

RDDs的介绍
Driver program
- main()方法,RDDs的定义和操作
- 管理很多节点,称作executors
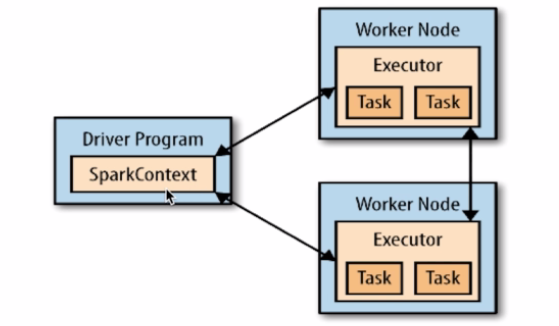
SparkContext
- Driver programs通过SparkContext对象访问Spark
- SparkContext对象代表和一个集群的连接
- 在Shell中SparkContext是自动创建好的,即sc
1 | //使用一下命令进入shell |
RDDs(弹性分布式数据集)
- 上述的lines就是一个弹性分布式数据集(RDD),其可以分布在集群内,但对使用者透明
- RDDs是Spark分发数据和计算的基础抽象类
- 一个RDD代表的是一个不可改变的分布式集合对象
- Spark中所有的计算都是通过对RDD的创建、转换、操作完成的
- 一个RDD由许多分片(partitions)组成,分片可以再不同节点上进行计算
- 分片是Spark的并行处理单元。Spark顺序的并行处理分片
RDDs的创建
通常使用parallelize()函数可以创建一个简单的RDD,测试用(为了方便观察结果)。
1 | scala> val rdd = sc.parallelize(Array(1,2,2,4),4) 最后一个4指的是并行度,默认是1 |
Scala基本知识:(详见Scala学习笔记)
小结
- Driver program 包含了程序的main方法,整个程序的入口的地方
- SparkContext 代表了和集群的连接,一般在程序的开头就出现
- RDDs 弹性分布式数据集,代表的就是一个数据集
RDD基本操作之转换(Transformation)
RDD的逐元素转换
- map():将map函数应用到RDD的每一个元素,返回一个新的RDD
val line2 = line1.map(word=>(word,1)) //word就代表迭代元素 - filter():返回只包含filter函数的值组成的新的RDD
val line2 = line1.filter(word。contains(“abc”)) //word就代表迭代元素 - flatMap():出入一个复杂元素,输出多个简单元素,类似数据的‘压扁’,按照一定的规则(指定函数)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30scala> val lines = sc.parallelize(Array("home Tom","hadoop Jack","look Kim"))
lines: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[5] at parallelize at <console>:24
scala> lines.foreach(println)
home Tom
hadoop Jack
look Kim
//注意对RDD本身的操作不影响其本身,因为是val定义的常量
scala> lines.flatMap(t=>t.split(" "))
res20: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at flatMap at <console>:27
scala> lines.foreach(println)
home Tom
hadoop Jack
look Kim
//必须使用新的常量来接收
scala> val newrdd = lines.flatMap(t=>t.split(" "))
newrdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[7] at flatMap at <console>:26
scala> newrdd.foreach(println)
home
Tom
hadoop
Jack
look
Kim
scala>
RDD的集合运算(交集并集)
1 | scala> val rdd1 = sc.parallelize(Array("one","two","three")) |
RDDs的基本操作之Action
- 在RDD上计算出来的一个结果
- 并把结果返回给driver program,save等等
reduce()
- 接收一个函数,作用在RDD两个类型相同的元素上,返回新元素
- 可以实现RDD中元素的累加、计数、和其他类型的聚集操作。
Collect()
- 遍历整个RDD,想driver program返回RDD内容
- 需要单机内存能够容纳下(因为需要拷贝给driver)
- 大数据处理要使用savaAsText方法
1
2
3
4
5
6
7
8scala> val rdd = sc.parallelize(Array(1,2,3,4))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd.collect()
res0: Array[Int] = Array(1, 2, 3, 4)
scala> rdd.reduce((x,y)=>x+y)
res1: Int = 10take(n)
- 返回RDD的n个元素(同时尝试访问最少的partitions)
- 返回的结果是无序的(在单节点时是有序的)
1
2
3
4
5scala> rdd.take(2)
res2: Array[Int] = Array(1, 2)
scala> rdd.take(3)
res3: Array[Int] = Array(1, 2, 3)top()
- 排序,默认使用RDD的比较器,可以自定义比较器
1
2scala> rdd.top(2)
res7: Array[Int] = Array(4, 3)foreach()
- 遍历RDD中的每个元素,并执行一次函数,如果为空则仅仅是遍历数据
- 一般结合print函数来遍历打印几何数据
RDDs的特性
血统关系图
- Spark维护着RDDs之间的依赖关系和创建关系,叫做血统关系图
- Spark使用血统关系图来计算每个RDD的需求和恢复的数据
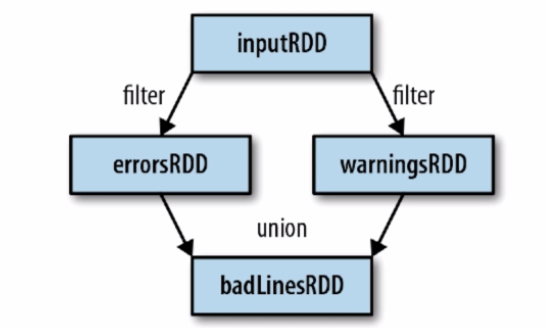
- 上述图示中经过了过个操作最后生成了一个RDD,如果badLinesRDD出错数据丢失,那么由于存在完整的血统关系图,所以可以将其恢复
<< 更多精彩尽在『程序萌部落』>>
<< https://www.cxmoe.com >>
延迟计算(Lazy Evaluation)
- Spark对RDDs的计算时 在第一次使用action操作的使用触发的
- 这种方式可以减少数据的传输
- Spark内部记实录metedata信息来完成延迟机制
- 加载数据本身也是延迟的,数据只有在最后被执行action操作时才会被加载
RDD.persist() 持久化
- 默认每次在RDDs上面进行action操作时,Spark都会重新计算
- 如果想重复使用一个RDD,就需要使用persist进行缓存,使用unpersist解除缓存
持久化缓存级别:
| 级别 | 空间占用 | CPU消耗 | 是否在内存 | 是否在硬盘 |
|---|---|---|---|---|
| MEMORY_ONLY | 高 | 低 | 在 | 不在 |
| MEMORY_ONLY_SER | 低 | 高 | 在 | 不在 |
| DISK_ONLY | 低 | 高 | 不在 | 在 |
| MEMORY_AND_DISK | 高 | 中 | Some | Some |
| MEMORY_AND_DISK_SER | 低 | 高 | Some | Some |
| MEMORY_AND_DISK 内存中放不下往硬盘放 | ||||
| MEMORY_AND_DISK_SER 内存中放不下往硬盘放(序列化的,故CPU消耗较大) |
键值对(KeyValue)RDDs
创建键值对RDDs
- 使用map()函数,返回键值对RDD
- 例如包含多行数据的RDD,将每行数据的第一个单词作为Key
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
scala> val lines = sc.textFile("/home/hadoop/look.sh")//注意这是错的,这样默认是取hdfs文件
scala> val lines = sc.textFile("file:///home/hadoop/look.sh")//用file://来指明取的系统文件
lines: org.apache.spark.rdd.RDD[String] = file:///home/hadoop/look.sh MapPartitionsRDD[5] at textFile at <console>:24
scala> lines.foreach(println)
#!/bin/bash
Jarinfo=$(ps -ef|grep java)
echo "$Jarinfo" | while read Line
do
#echo $Line;
#echo ${Line##*:}
Jarstr=${Line##*:}
Ishere=$(echo $Jarstr | grep $1 )
if [[ "$Ishere" != "" ]]
then
echo YES 1>
exit 1
fi
done
scala> val pairs = lines.map(line=>(line.split(" ")(0),line))
pairs: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[6] at map at <console>:26
scala> pairs.foreach(println)
(#!/bin/bash,#!/bin/bash)
(Jarinfo=$(ps,Jarinfo=$(ps -ef|grep java))
(echo,echo "$Jarinfo" | while read Line)
(do,do )
( #echo, #echo $Line;)
( #echo, #echo ${Line##*:})
( Jarstr=${Line##*:}, Jarstr=${Line##*:})
( Ishere=$(echo, Ishere=$(echo $Jarstr | grep $1 ))
( if, if [[ "$Ishere" != "" ]])
( then, then)
( echo, echo YES 1>)
( exit, exit 1 )
( fi, fi)
(done,done)键值对常见操作函数
函数名 作用 reduceByKey(func) 把相同key的value进行结合,key不变,是计算 groupByKey(func) 把相同key的value进行分组,key不变,仅分组 combineByKey(,,,) mapValues(func) 将map操作作用于Values,进对Values进行操作 flatMapValues(func) 将flatMap(扩展)操作作用于Values keys 仅返回键的值(RDD.keys) values 仅返回值的值(RDD.values) sortBtKey() 按照Key来排序
1 | scala> var rdd = sc.parallelize(Array((1,2),(3,4),(3,6))) |
combineByKey()
特点:最常用的基于key的聚合函数,返回的类型可以与输入的类型不一样
参数:createCombiner,mergeValue,mergeCombiners,partitioner
应用:许多基于key的聚合函数都用到了,例如groupByKey底层就应用到了
注意:
- 遍历分片中的元素,元素的key要么之前见过要么没见过
- (某个分区)如果是这个分区中的新key,那么就是用createCombiner()函数
- (某个分区)如果是这个分区中已经见过的key,那么就是用mergeValue()函数
- (全部分区)合计分区结果时,使用mergeCombiner()函数
示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18注意:combineByKey(x=>(1,x),,,) // x 表示的是Values
scala> var rdd = sc.parallelize(Array(("Tom",82),("Tom",78),("Mike",76),("Mike",74)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[6] at parallelize at <console>:24
//可以求每个人的成绩之和+课程数目(即一次计算多个指标)
scala> val rst = rdd.combineByKey(x=>(1,x),(item:(Int,Int),new)=>(item._1+1,item._2+new),(a:(Int,Int),b:(Int,Int))=>(a._1+b._1,a._2+b._2))
scala> rst.foresch(println)
(Tom,(2,160))
(Mike,(2,150))
附:验证格式可以用case
scala> rdd.map{case(name,score)=>(name,score,"valid ok")}.foreach(println)
(Tom,82,valid ok)
(Tom,78,valid ok)
(Mike,76,valid ok)
(Mike,74,valid ok)
小结
- Spark的介绍:重点是即与内存
- Spark的安装:重点是开发环境的搭建(sbt打包)
- RDDs的介绍:重点Transformations,Actions
- RDDs的特性:重点是血统关系图和延迟[lazy]计算
- 键值对RDDs
后续
- Spark的架构
- Spark的运行过程
- Spark程序的部署过程
😒 留下您对该文章的评价 😄
