

GraphX介绍
GraphX应用背景
Spark GraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求。
众所周知·,社交网络中人与人之间有很多关系链,例如Twitter、Facebook、微博和微信等,这些都是大数据产生的地方都需要图计算,现在的图处理基本都是分布式的图处理,而并非单机处理。Spark GraphX由于底层是基于Spark来处理的,所以天然就是一个分布式的图处理系统。
图的分布式或者并行处理其实是把图拆分成很多的子图,然后分别对这些子图进行计算,计算的时候可以分别迭代进行分阶段的计算,即对图进行并行计算。下面我们看一下图计算的简单示例:
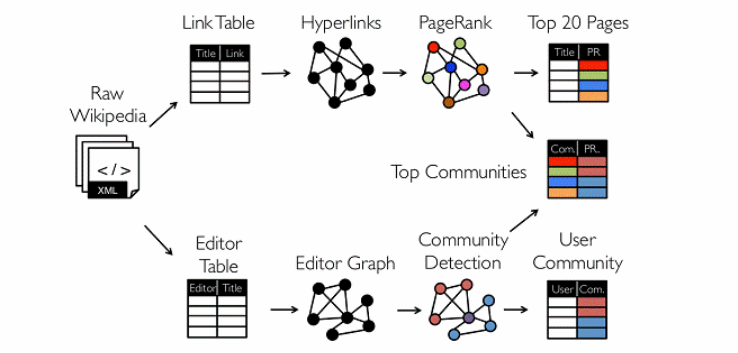
从图中我们可以看出:拿到Wikipedia的文档以后,可以变成Link Table形式的视图,然后基于Link Table形式的视图可以分析成Hyperlinks超链接,最后我们可以使用PageRank去分析得出Top Communities。在下面路径中的Editor Graph到Community,这个过程可以称之为Triangle Computation,这是计算三角形的一个算法,基于此会发现一个社区。从上面的分析中我们可以发现图计算有很多的做法和算法,同时也发现图和表格可以做互相的转换。
GraphX的框架
设计GraphX时,点分割和GAS都已成熟,在设计和编码中针对它们进行了优化,并在功能和性能之间寻找最佳的平衡点。如同Spark本身,每个子模块都有一个核心抽象。GraphX的核心抽象是Resilient Distributed Property Graph,一种点和边都带属性的有向多重图。它扩展了Spark RDD的抽象,有Table和Graph两种视图,而只需要一份物理存储。两种视图都有自己独有的操作符,从而获得了灵活操作和执行效率。
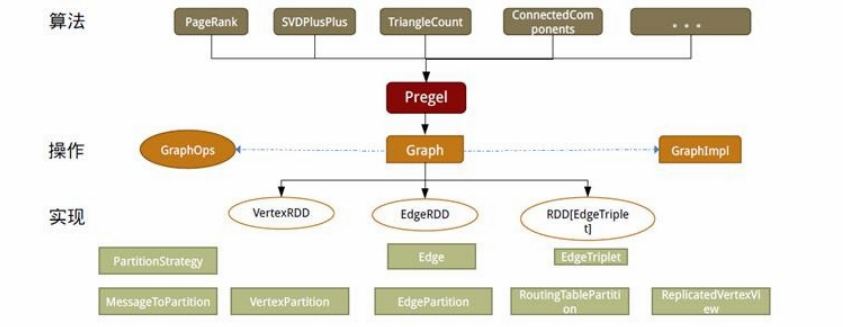
如同Spark,GraphX的代码非常简洁。GraphX的核心代码只有3千多行,而在此之上实现的Pregel模式,只要短短的20多行。GraphX的代码结构整体下图所示,其中大部分的实现,都是围绕Partition的优化进行的。这在某种程度上说明了点分割的存储和相应的计算优化,的确是图计算框架的重点和难点。
发展历程
l早在0.5版本,Spark就带了一个小型的Bagel模块,提供了类似Pregel的功能。当然,这个版本还非常原始,性能和功能都比较弱,属于实验型产品。
l到0.8版本时,鉴于业界对分布式图计算的需求日益见涨,Spark开始独立一个分支Graphx-Branch,作为独立的图计算模块,借鉴GraphLab,开始设计开发GraphX。
l在0.9版本中,这个模块被正式集成到主干,虽然是Alpha版本,但已可以试用,小面包圈Bagel告别舞台。1.0版本,GraphX正式投入生产使用。

值得注意的是,GraphX目前依然处于快速发展中,从0.8的分支到0.9和1.0,每个版本代码都有不少的改进和重构。根据观察,在没有改任何代码逻辑和运行环境,只是升级版本、切换接口和重新编译的情况下,每个版本有10%~20%的性能提升。虽然和GraphLab的性能还有一定差距,但凭借Spark整体上的一体化流水线处理,社区热烈的活跃度及快速改进速度,GraphX具有强大的竞争力。
GraphX实现分析
如同Spark本身,每个子模块都有一个核心抽象。GraphX的核心抽象是Resilient Distributed Property Graph,一种点和边都带属性的有向多重图。它扩展了Spark RDD的抽象,有Table和Graph两种视图,而只需要一份物理存储。两种视图都有自己独有的操作符,从而获得了灵活操作和执行效率。

GraphX的底层设计有以下几个关键点。
对Graph视图的所有操作,最终都会转换成其关联的Table视图的RDD操作来完成。这样对一个图的计算,最终在逻辑上,等价于一系列RDD的转换过程。因此,Graph最终具备了RDD的3个关键特性:Immutable、Distributed和Fault-Tolerant,其中最关键的是Immutable(不变性)。逻辑上,所有图的转换和操作都产生了一个新图;物理上,GraphX会有一定程度的不变顶点和边的复用优化,对用户透明。
两种视图底层共用的物理数据,由RDD[Vertex-Partition]和RDD[EdgePartition]这两个RDD组成。点和边实际都不是以表Collection[tuple]的形式存储的,而是由VertexPartition/EdgePartition在内部存储一个带索引结构的分片数据块,以加速不同视图下的遍历速度。不变的索引结构在RDD转换过程中是共用的,降低了计算和存储开销。
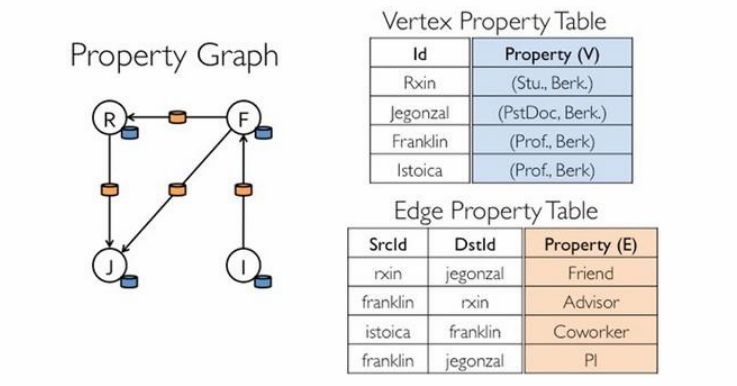
图的分布式存储采用点分割模式,而且使用partitionBy方法,由用户指定不同的划分策略(PartitionStrategy)。划分策略会将边分配到各个EdgePartition,顶点Master分配到各个VertexPartition,EdgePartition也会缓存本地边关联点的Ghost副本。划分策略的不同会影响到所需要缓存的Ghost副本数量,以及每个EdgePartition分配的边的均衡程度,需要根据图的结构特征选取最佳策略。目前有EdgePartition2d、EdgePartition1d、RandomVertexCut和CanonicalRandomVertexCut这四种策略。
存储模式
图存储模式
巨型图的存储总体上有边分割和点分割两种存储方式。2013年,GraphLab2.0将其存储方式由边分割变为点分割,在性能上取得重大提升,目前基本上被业界广泛接受并使用。
边分割(Edge-Cut):每个顶点都存储一次,但有的边会被打断分到两台机器上。这样做的好处是节省存储空间;坏处是对图进行基于边的计算时,对于一条两个顶点被分到不同机器上的边来说,要跨机器通信传输数据,内网通信流量大。
点分割(Vertex-Cut):每条边只存储一次,都只会出现在一台机器上。邻居多的点会被复制到多台机器上,增加了存储开销,同时会引发数据同步问题。好处是可以大幅减少内网通信量。
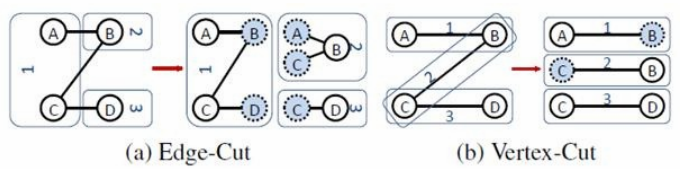
虽然两种方法互有利弊,但现在是点分割占上风,各种分布式图计算框架都将自己底层的存储形式变成了点分割。主要原因有以下两个。
- 磁盘价格下降,存储空间不再是问题,而内网的通信资源没有突破性进展,集群计算时内网带宽是宝贵的,时间比磁盘更珍贵。这点就类似于常见的空间换时间的策略。
- 在当前的应用场景中,绝大多数网络都是“无尺度网络”,遵循幂律分布,不同点的邻居数量相差非常悬殊。而边分割会使那些多邻居的点所相连的边大多数被分到不同的机器上,这样的数据分布会使得内网带宽更加捉襟见肘,于是边分割存储方式被渐渐抛弃了。
<< 更多精彩尽在『程序萌部落』>>
<< https://www.cxmoe.com >>
GraphX存储模式
Graphx借鉴PowerGraph,使用的是Vertex-Cut(点分割)方式存储图,用三个RDD存储图数据信息:
lVertexTable(id, data):id为Vertex id,data为Edge data
lEdgeTable(pid, src, dst, data):pid为Partion id,src为原定点id,dst为目的顶点id
lRoutingTable(id, pid):id为Vertex id,pid为Partion id
点分割存储实现如下图所示:

计算模式
图计算模式
目前基于图的并行计算框架已经有很多,比如来自Google的Pregel、来自Apache开源的图计算框架Giraph/HAMA以及最为著名的GraphLab,其中Pregel、HAMA和Giraph都是非常类似的,都是基于BSP(Bulk Synchronous Parallell)模式。
Bulk Synchronous Parallell,即整体同步并行,它将计算分成一系列的超步(superstep)的迭代(iteration)。从纵向上看,它是一个串行模式,而从横向上看,它是一个并行的模式,每两个superstep之间设置一个栅栏(barrier),即整体同步点,确定所有并行的计算都完成后再启动下一轮superstep。
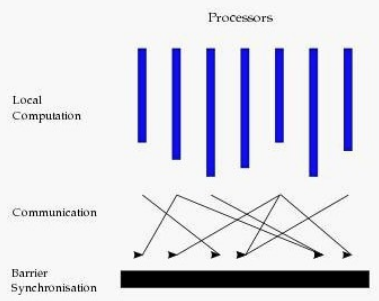
每一个超步(superstep)包含三部分内容:
- 计算compute:每一个processor利用上一个superstep传过来的消息和本地的数据进行本地计算;
- 消息传递:每一个processor计算完毕后,将消息传递个与之关联的其它processors
- 整体同步点:用于整体同步,确定所有的计算和消息传递都进行完毕后,进入下一个superstep。
GraphX计算模式
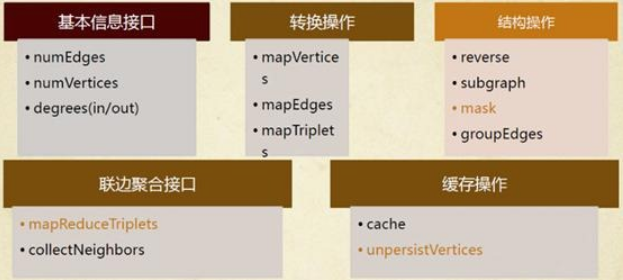
如同Spark一样,GraphX的Graph类提供了丰富的图运算符,大致结构如下图所示。可以在官方GraphX Programming Guide中找到每个函数的详细说明,本文仅讲述几个需要注意的方法。
图的缓存
每个图是由3个RDD组成,所以会占用更多的内存。相应图的cache、unpersist和checkpoint,更需要注意使用技巧。出于最大限度复用边的理念,GraphX的默认接口只提供了unpersistVertices方法。如果要释放边,调用g.edges.unpersist()方法才行,这给用户带来了一定的不便,但为GraphX的优化提供了便利和空间。参考GraphX的Pregel代码,对一个大图,目前最佳的实践是:

大体之意是根据GraphX中Graph的不变性,对g做操作并赋回给g之后,g已不是原来的g了,而且会在下一轮迭代使用,所以必须cache。另外,必须先用prevG保留住对原来图的引用,并在新图产生后,快速将旧图彻底释放掉。否则,十几轮迭代后,会有内存泄漏问题,很快耗光作业缓存空间。
邻边聚合
mrTriplets(mapReduceTriplets)是GraphX中最核心的一个接口。Pregel也基于它而来,所以对它的优化能很大程度上影响整个GraphX的性能。mrTriplets运算符的简化定义是:

它的计算过程为:map,应用于每一个Triplet上,生成一个或者多个消息,消息以Triplet关联的两个顶点中的任意一个或两个为目标顶点;reduce,应用于每一个Vertex上,将发送给每一个顶点的消息合并起来。
mrTriplets最后返回的是一个VertexRDD[A],包含每一个顶点聚合之后的消息(类型为A),没有接收到消息的顶点不会包含在返回的VertexRDD中。
在最近的版本中,GraphX针对它进行了一些优化,对于Pregel以及所有上层算法工具包的性能都有重大影响。主要包括以下几点。
- Caching for Iterative mrTriplets & Incremental Updates for Iterative mrTriplets:在很多图分析算法中,不同点的收敛速度变化很大。在迭代后期,只有很少的点会有更新。因此,对于没有更新的点,下一次mrTriplets计算时EdgeRDD无需更新相应点值的本地缓存,大幅降低了通信开销。
- Indexing Active Edges:没有更新的顶点在下一轮迭代时不需要向邻居重新发送消息。因此,mrTriplets遍历边时,如果一条边的邻居点值在上一轮迭代时没有更新,则直接跳过,避免了大量无用的计算和通信。
- Join Elimination:Triplet是由一条边和其两个邻居点组成的三元组,操作Triplet的map函数常常只需访问其两个邻居点值中的一个。例如,在PageRank计算中,一个点值的更新只与其源顶点的值有关,而与其所指向的目的顶点的值无关。那么在mrTriplets计算中,就不需要VertexRDD和EdgeRDD的3-way join,而只需要2-way join。
所有这些优化使GraphX的性能逐渐逼近GraphLab。虽然还有一定差距,但一体化的流水线服务和丰富的编程接口,可以弥补性能的微小差距。
进化的Pregel模式
GraphX中的Pregel接口,并不严格遵循Pregel模式,它是一个参考GAS改进的Pregel模式。定义如下:

这种基于mrTrilets方法的Pregel模式,与标准Pregel的最大区别是,它的第2段参数体接收的是3个函数参数,而不接收messageList。它不会在单个顶点上进行消息遍历,而是将顶点的多个Ghost副本收到的消息聚合后,发送给Master副本,再使用vprog函数来更新点值。消息的接收和发送都被自动并行化处理,无需担心超级节点的问题。
常见的代码模板如下所示:

可以看到,GraphX设计这个模式的用意。它综合了Pregel和GAS两者的优点,即接口相对简单,又保证性能,可以应对点分割的图存储模式,胜任符合幂律分布的自然图的大型计算。另外,值得注意的是,官方的Pregel版本是最简单的一个版本。对于复杂的业务场景,根据这个版本扩展一个定制的Pregel是很常见的做法。
图算法工具包
GraphX也提供了一套图算法工具包,方便用户对图进行分析。目前最新版本已支持PageRank、数三角形、最大连通图和最短路径等6种经典的图算法。这些算法的代码实现,目的和重点在于通用性。如果要获得最佳性能,可以参考其实现进行修改和扩展满足业务需求。另外,研读这些代码,也是理解GraphX编程最佳实践的好方法。
作者:石山园
出处:http://www.cnblogs.com/shishanyuan/
😒 留下您对该文章的评价 😄
