

原文名:Cluster Stability and the Use of Noise in Interpretation of Clustering
中文译:聚类的稳定性和在聚类解释中添加噪声
源刊载:IEEE Symposium on Information Visualization , 2001 :23
机构名:Sandia National Laboratories 桑迪亚国家实验室,US
研究点:
- Clustering algorithms
- Data visualization
- Stability analysis
- Algorithm design and analysis
- Best practices摘要
本文介绍了一种适合挖掘超大型数据库的聚类和排序ordination算法,包括微阵列表达式研究microarray expression studies产生的数据库,并对其稳定性进行了分析。
在实际条件下,利用一个酵母细胞周期实验,对6000个基因进行实验,并对每个基因进行18个实验测量。
将数据库对象分配X、Y坐标及顺序的过程,在随机启动条件下,以及在开始相似度估计中对小扰动的处理是稳定的。
对聚类通常共同定位的方式进行了仔细的分析,而在不同的初始条件下偶尔出现的大位移则被证明在解释数据时非常有用。
当只报告一个聚类时,就会丢失这种额外的稳定性信息,这是目前已被接受的实践。
然而,在分析大型数据收集的计算机聚类时,人们认为这里提出的方法应该成为最佳实践的标准部分。
Introduction
我们感兴趣的是在大量的实验数据中发现意想不到的关系。
不幸的是,我们很容易看到虚幻的模式illusory patterns
我们的思想是建立在寻找模式的基础上的,即使我们知道感知到的模式仅仅是随机的工件,我们也会这样做。
因此,我们感兴趣的模式必须进行一些测试,这些测试表明,如果我们从另一个类似的数据集开始,或者,可能是由于添加了少量的噪音而随机干扰的数据,它们肯定会再次发生。
我们使用计算机来查看这些大型数据集,因此我们有必要相信我们的计算工具是可靠的,特别是在我们的例子中,它们使用随机数。
我们想知道的结果是对工具内部随机过程的细节不敏感;
也就是说,我们想知道我们使用的工具是稳定的,在每次的使用中。
当然,我们希望这些工具是实用的,对实践科学家有用,他们想知道这些模式是真实的,并且它们可能指向世界上的一些物理事实或重要的过程。
几个世纪的实践证明,最后一个问题只能通过仔细控制的实验来回答。
在这里,我们必须把我们的工具所发现的关系的测试和解释留给实验家。
相反,我们的目的是解决发现潜在重要模式的过程,以及对过程本身的可靠性的调查,以及过程对初始数据的细微变化的敏感性。
我们将报告对一个特定数据挖掘工具的可靠性和灵敏度的各种计算调查,VxInsight1998 使用的是中等大小的微阵列数据集。
VxInsight使用一个地形隐喻来描述大量的数据,通过在地形上相互靠近,来总结相似元素的簇。
二维的星团被想象成由山谷和开阔空间分隔的山脉和山丘。
山脉的高度表明了每座山下聚集的元素数量。
山脉之间的局部分组和分离也包含了关于集群间相似性的信息。
在被广泛隔离的山脉中,数据元素的相似性要小于邻近山脉的数据元素。
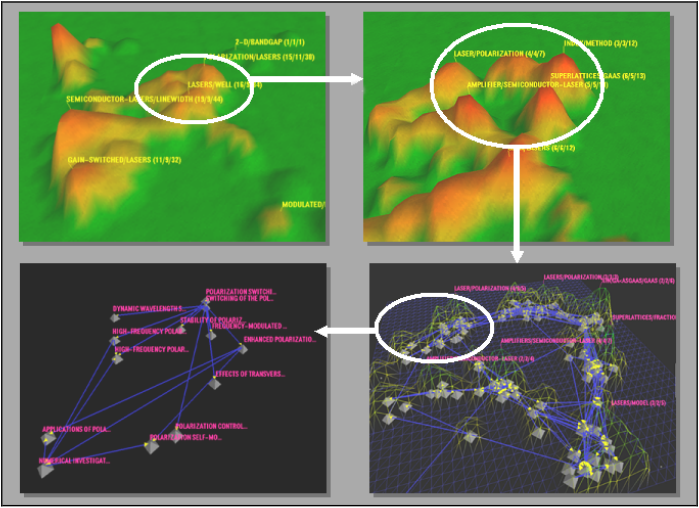
图一。在VxInsight中关系的持续变化
不像自组织的maps4、k-means5、或约克的快速聚类6.7,我们的方法不需要预先猜测应该创建多少个聚类。
而且,像地形一样的聚类可以表示 比 仅仅列出聚类元素 更多的信息。
在山下的局部结构会显示出更细、更细的关系,当将其放大到地形的表示时(图1),数据对象在特定的聚类或层次结构中并不是显式的成员。
物体的位置是通过在二维空间中的连通图的能量最小化来确定的。
对每个数据元素的X、Y坐标的赋值是一个我们称之为序化的过程。
本文的主要主题是我们的序化过程的稳定性。
简要地介绍了我们的力导向序化算法的随机元素的稳定性特征。
这些特征在一系列的实验中被研究,这些实验用不同的随机起始条件重新排列相同的数据集,并比较(从视觉上和统计上)结果。
正如在结果和讨论部分中所描述的,序化算法展示了可预测的、可理解的行为。
在确定该工具可接受的稳定之后,我们研究了在相似关系中添加噪声的影响,在序化过程的输入阶段。
正如预期的那样,在真实的数据集下,某些聚类比其他聚类更稳定。
重要的是,一些聚类不仅保留了相同的成员,而且在地形图中保持了物理上的接近。
其他聚类往往会伴随较大的位移,这可以通过在地形图中聚类间强相似性连接来理解。
In the Results and Discussion section, we describe how this analysis suggests important strategies for testing the robustness of clustering algorithms.
在结果和讨论部分中,我们描述了该分析如何提出测试聚类算法的健壮性的重要策略。
方法
如何生成一个VxInsight图
图2显示了数据必须通过的一般流程,以生成VxInsight图。
一个典型的数据库,在图中表示为表格,它由几千个元素(行)组成,其中一个或多个属性为(列)。
必须对这些数据进行处理,以计算每一对数据元素的相似性,然后用它们来构造一个抽象图。
在这个节点和弧的图中,节点表示单个的数据元素,而弧是元素之间的相似性。
序化过程将每个数据元素分配给抽象可视化表面的X、Y位置。
最后,这些坐标被用来生成山地地形。
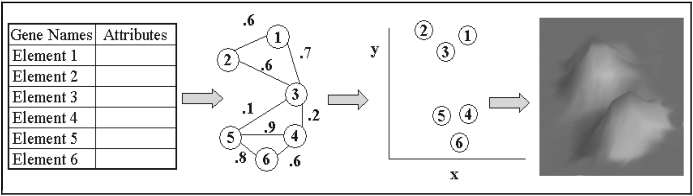
图二。将数据处理成VxInsight图
选择一个数据集
在我们的实验中,我们选择了一个现成的数据集http://genomewww.stanford。edu/cellcycle/data/rawdata,这是一个包含大约6000个数据元素的表格(酵母中的基因)。
我们选择了这个数据集的一个子集,在细胞生长分裂的过程中,对这些基因的活动进行了18次测量。
这些数据足够大,可以提供数据挖掘技术发现的机会,而且远远超出了测试聚类方法的玩具toy问题。
此外,酵母数据集已经被很好地研究过,某些基因也被认为是一起工作的,应该把它们聚集在一起,可以作为对我们算法的简单测试。
最后,研究这一数据集使人们有可能对未被研究的基因的功能进行重要的预测,这些基因聚集在这些具有已知功能的基因附近。
重要的是,这些预测可以通过检验这些数据最初发布以来发表的文献来验证;
其中很多都可以在网上找到,用基因名索引,例如,可以看到http://www.proteome.com或斯坦福网站http://基因组-www.stanford。edu/cgi-bin/sg/search。
计算基因的相似性
电子表格中的每一列都记录了单个显微镜载片上6000个点的相对亮度。
除了受控制的变量之外,各种各样的条件将会系统地改变这些测量值。
例如,一张幻灯片的整体亮度可能因位置不同的材料而不同,处理条件略有不同,或者在扫描光强度方面存在差异。
为了弥补这些影响,每一张幻灯片的测量值(在扩展表中的一个列)通过减去这张幻灯片的中值来进行标准化,然后除以四分位范围(75百分位数和25%亮度值之间的差值)。
这种健壮的标准化对异常值的敏感度要低于标准化,通过减去平均值并除以标准偏差8。
皮尔逊的相关系数9被用来计算每一对基因之间的相似性。
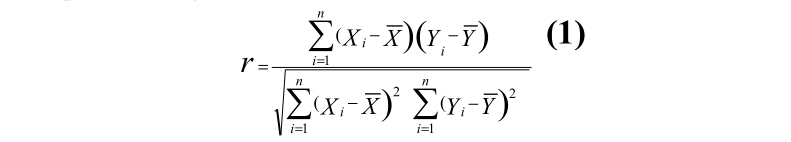
没有相似之处的基因将会有接近于0的值,而与之相似的基因将有接近于1的值。
Using the raw correlations unduly weights the low similarities and does not adequately represent the information content contained in a strong similarity.
使用原始的相关性对弱相关进行了过度的加权,并且不能充分地表示强相关的信息内容。
The non-linearity of this information, or rareness, is extreme and can change the total range of observed similarity weights by orders of magnitude.
该信息的非线性,或罕见性,是极端的并且可以按数量级改变观察到的相似度值的总范围。
We created all of the clusters reported here using gene pair similarities based on the t-statistic of the correlation coefficient, not on the correlation coefficient itself
我们使用基于相关系数的t统计量的基因对的相似度 来创建所有的聚类,而不是相关系数本身。
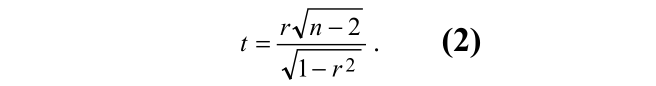
这种转换具有逻辑支持,在实践中运行良好,并且易于计算。
我们认为,至少对于微阵列(DNA微阵列)实验来说,在所有的聚类分析中,都应该替换直接基于相关性的相似性。
在这个实验中,每6000个基因中都记录了20个最强烈的正相关。
最后,对于6000个基因中的每一个,基因的名称,它相关的基因的名称和相关的t统计量都被写入到一个文件中,供序化程序使用。
重要的是要使用大量的相似点来确保有序的精细结构被捕获。
然而,我们发现,对具有最强烈相似性的基因的放置进行的视觉检查,为评估这些序列的质量和理解它们的结构提供了一种方式。
例如,在图3中,强链接表明红色聚类可以很好地放置在山脊的两侧(由黄色、粉色和浅蓝色定义)。
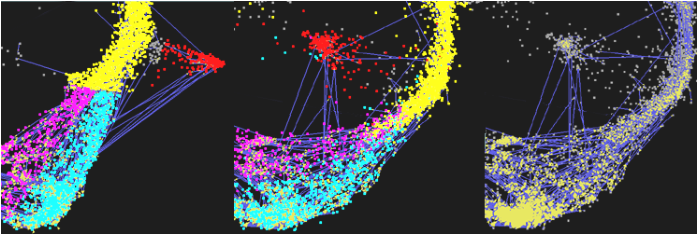
图3:两个随机运行(左、中)显示红色集群交换位置。
强链接(蓝线)表明,顺序是可以接受的。
第三幅图像更清晰地显示了山脊内的强连接密度。
确定一个合适的阈值来确定高度相关的基因是有问题的。
1963年,为了报告相关性的统计意义,奥斯特尔[Ostel, 1963] 的常见做法是测试下一种情况
Ho : The observed n-sample correlation is consistent with observing two processes with a true correlation 0 = ρ ,
观察到的n-样本相关性与观察两个具有真相关的过程是一致的,
using a t-test with 2 n degrees of freedom and reject the hypothesis with some level of confidence α .
使用n-2自由度的t-test测试,并以一定程度的置信度α拒绝这个假设。
然而,有6000个基因我们有1800万对相关性。
即使使用了0.001的置信水平,假设真正的相关性为0时,我们就会期望有36000对相关性超过临界值。
确定一组高度相关的基因(特别是当n很大),更好的方法是进行动力分析a power analysis,这需要一些假设的选择实际相关,ρ0,和一些可接受的机会不是检测对真正有关联的基因ρ0由于观测值的变化。
例如,我们选择了ρ0=0.9 作为实际相关度,并且假设我们需要保留在二十次测量中有此相关度大于一次的基因对(这时β=0.05)。
对于测试Ho的上述公式 仅仅在ρ0=0时有效。当ρ0≠0,可以使用基于费雪10的近似值,which把r转化为标准的Z统计分量(Zρ0和方差σ2)
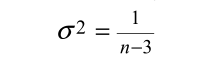
对于Z,有如下: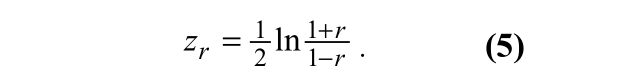
因此,接收pair的关键是他们是强相关的,根据我们的规范,我们会错误地拒绝一种相关性在20%的情况下,当真正的潜在相关性是ρ0=0.9且n=18:
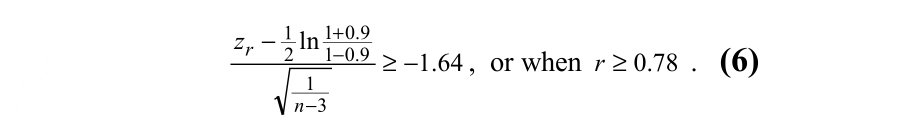
这个临界值对应于 α < 0.0005。匹配该规范的一对基因被保存下来,以便稍后在VxInsight中显示。
VxInsight序化程序
序化程序通过考虑整个集合中的对象之间的所有相似性来确定数据对象的空间位置,图4显示了具有许多相似链接(边)的对象在地图上聚集在一起;而那些几乎没有或没有相似链接的对象是分开的。
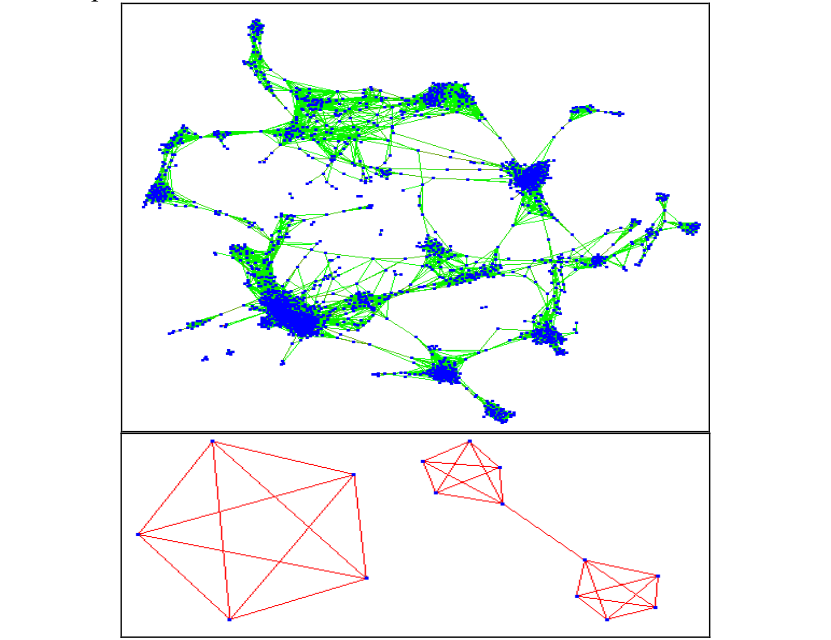
2000个顶点图(顶部)的布局,以及已知的K 5和双K 5(底部)的解决方案。
一个抽象的,边缘加权的图,G=(V,E),是用一个节点列表和它们的相似点生成的,其中顶点V对应于数据对象,相似点对应于加权边,E,有大量的文献用于图形绘制和布局算法11-19
Fruchterman和Reingold 12的工作与我们的方法特别相关。
在开发和实现我们的算法时,我们遵循了四个重要原则:
- 由边连接的顶点应该相互靠近。
- 非连接的顶点应该相互远离。
- 结果应该对随机的初始条件不敏感。
- 计算的复杂性应该降低到最小值。
这些原则非常重要,我们将详细讨论每一个原则。
原则1和2
Fruchterman等人计算了吸引力和排斥力。然后,这些术语用于为图形顶点生成新的位置。
我们的算法将吸引力和排斥项结合成一个势能方程(方程式3),第一个部分,在括号中,是由于连接顶点之间的吸引;第部分是排斥项。
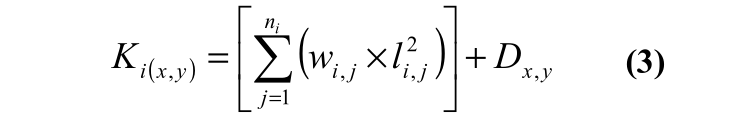
Ki(x,y) = 一个顶点在一个特定的x,y位置的能量
ni = 连接到顶点i的边数
wi,j = 顶点i与顶点j连接的顶点之间的边权值。
l2i,j = 顶点i的平方距离和边j的另一端的顶点之间的距离。
Dx,y = 一个力项与xy附近顶点的密度成比例。在我们的顺序中,方程3在三个阶段中以迭代的方式逐渐被最小化。
第一阶段通过将顶点扩展到它们最终所属的一般区域,从而减少系统中的自由能量。
下一阶段类似于模拟退火算法中出现的淬火步骤,节点会进行更小的随机跳跃,以最小化它们的能量方程式。
最后一个是酝酿中的阶段,详细的地方修正。
所有的运动都是随机的;
每个顶点都可以从当前位置跳转到一个新的、随机的位置。
如果移动减少了顶点的势能,那么顶点就被允许停留在新的位置。
否则,顶点将保留旧位置到下一个迭代的位置。
其他更复杂的技术,包括梯度下降法和动量项法,在理论上很具有吸引力。
然而,成千上万个顶点的能量表面是如此的混乱(在空间上和时间上),在实践中,我们发现更简单的方法表现更好。
请注意,对于每个顶点,只有它自己的能量被考虑,这是贪婪算法的一个特征,它只会间接地导致整个系统的全局最小化。
然而,系统的总能量,见方程4,仍然可以作为算法终止的标准。

文献11,16,17讨论了许多其他的终止标准,其中一些没有明确地遵循总能量。
例如,Eades11建议简单地运行固定数量的迭代,在它们的情况下是100。
我们发现,对于更复杂的图形,800个迭代很好地工作。
我们通常处理的图形有上万个顶点。
本文讨论的图中有6000个顶点,需要90秒才能完成600 MHz的奔腾III的800次迭代。
很明显,尽量减少潜在的能量应该会导致与我们的前两个原则相符合的ordinations。
吸引项激励点的移动,将使(带权的)强相关顶点之间的边的长度的最小化。
第二项,Dx,y,是基于附近顶点的局部密度的力,当顶点移动到不那么拥挤的区域时,它被最小化。
为了减少这两部分的计算,一个顶点必须接近它的连接顶点,并且与非连接的顶点保持一定的距离。
原则3
一个序化过程可以很容易地以防止平稳过渡到正确的答案的方式开始。
也就是说,算法会被困在局部极小值中,并且很可能在计算的早期被迫趋向局部极小值。
问题是,初始的配置可能会导致一些应该彼此靠近的顶点,被一个大的障碍分隔开。
各种随机技术被用来避免这个问题。
例如模拟退火,它采用一定概率来决定,是否采取增加节点相关能量的动作。
这种技术允许顶点克服与局部极小值相关的障碍,以寻找更低的能量状态。
在对我们的能量方程式进行检查后,我们可以清楚地看到,通过直接求解单个顶点的能量的位置,可以使其迅速地通过一个能量屏障。
在我们的算法中,我们已经成功地使用了这种分析方法来避免局部极小值。
在过程的早期实现一个良好的配置,独立于初始配置,对于有效的序化是十分重要的,这也契合原则3。
模拟退火算法的原理概述
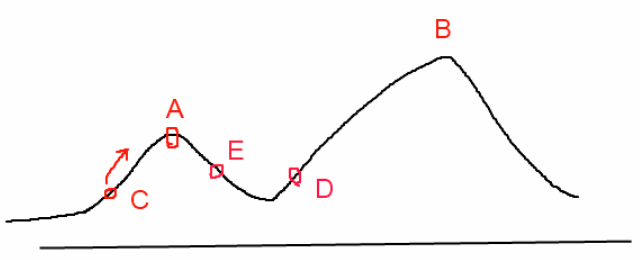
爬山法是一种贪婪的方法,其目标是要找到函数的最大值,若初始化时,初始点的位置在C处,则会寻找到附近的局部最大值A点处,由于A点出是一个局部最大值点,故对于爬山法来讲,该算法无法跳出局部最大值点。若初始点选择在D处,根据爬山法,则会找到全部最大值点B。这一点也说明了这样基于贪婪的爬山法是否能够取得全局最优解与初始值的选取由很大的关系。对于这个优化问题,其大致图像如下图所示:
其目标是要找到函数的最大值,若初始化时,初始点的位置在C处,则会寻找到附近的局部最大值A点处,由于A点出是一个局部最大值点,故对于爬山法来讲,该算法无法跳出局部最大值点。若初始点选择在D处,根据爬山法,则会找到全部最大值点B。这一点也说明了这样基于贪婪的爬山法是否能够取得全局最优解与初始值的选取由很大的关系。
模拟退火算法(Simulated Annealing, SA)的思想借鉴于固体的退火原理,当固体的温度很高的时候,内能比较大,固体的内部粒子处于快速无序运动,当温度慢慢降低的过程中,固体的内能减小,粒子的慢慢趋于有序,最终,当固体处于常温时,内能达到最小,此时,粒子最为稳定。模拟退火算法便是基于这样的原理设计而成。
模拟退火算法从某一较高的温度出发,这个温度称为初始温度,伴随着温度参数的不断下降,算法中的解趋于稳定,但是,可能这样的稳定解是一个局部最优解,此时,模拟退火算法中会以一定的概率跳出这样的局部最优解,以寻找目标函数的全局最优解。如上图中所示,若此时寻找到了A点处的解,模拟退火算法会以一定的概率跳出这个解,如跳到了D点重新寻找,这样在一定程度上增加了寻找到全局最优解的可能性。
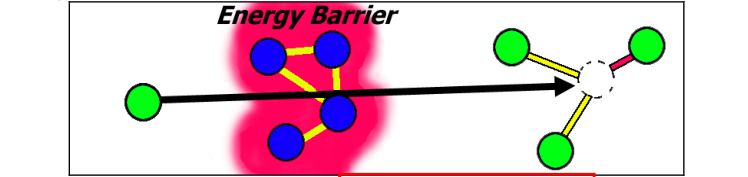
我们通过将顶点移动到方程3中指定的方向来达到这个结果。
然而,为了跳过能量屏障,一小部分顶点忽略了排斥项,并在计算上将吸引项最小化。
这是通过在所有连接的顶点上计算加权的中心来实现的。
然后顶点跳到那个计算的质心,不管是否有任何可能的能量增加,如图5所示。
图五,通过忽略密度项来跳过障碍。
在冷却过程中,障碍跳跃是与冷却时间相联系的,在淬火期间,障碍跳跃的设置频率从25%下降到10%,在炖煮(simmer)阶段根本不使用。
在开始时,为了达到稳定性而在随机的初始阶段使用较高的频率。
糟糕的初始位置或初始的错误的跳跃,将不可逆转地改变一个纯粹随机算法的结果。由于这一过程的修正性质,极大地减轻了上述的影响。
图6显示了两个随机运行的图像。
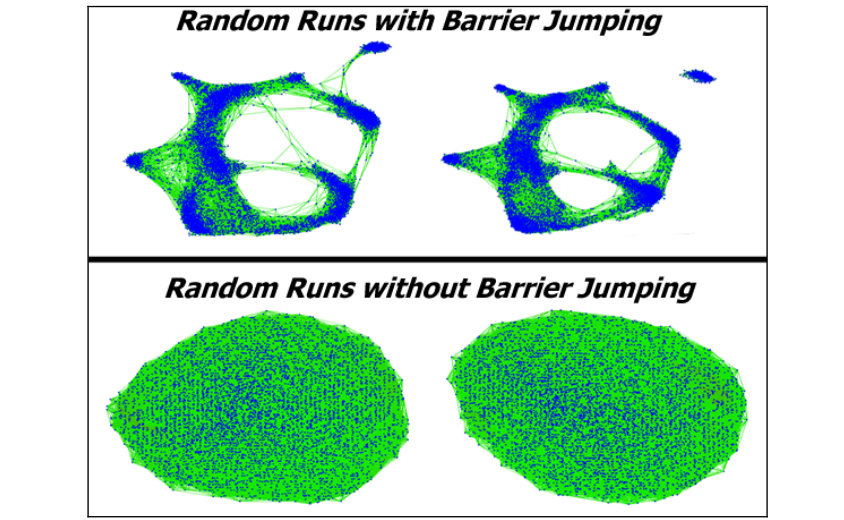
第一行的使用障碍跳跃,第二行没有。
我们可以看到使用障壁跳技术取得的优异的重复性。
第二行显示,6000个顶点被绝望地困在一个局部极小值的网络中。
图7中的柱状图提供了进一步的支持,即障碍跳跃提高了随机迭代求解器的可重复性。
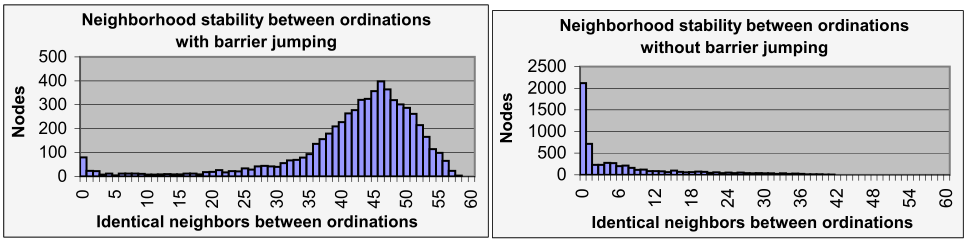
对于本文的直方图,我们想通过计算在地图的一小部分(1%)内的相同邻居的数量来测量有序算法的稳定性。
这些图包含了6000个基因,所以对于每一个基因,我们测量了60个最近的基因中有多少在迭代过程保持不变。
(如图所示,图中柱状图的和应为6000,上面的表示大部分节点在布局结束后都能发现45个左右的相同的邻居节点,下面的表示大部分节点在每次布局后都没有/0个相同的邻居节点)
<< 更多精彩尽在『程序萌部落』>>
<< https://www.cxmoe.com >>
原则4
计算Dxy的蛮力方法肯定不符合我们的第四个原则。
因为每个顶点都必须检查它对所有其他顶点的位置,这个简单的方法对于每一个Dxy的确定都要进行|V|次比较。
当每个节点都必须计算出Dxy在特定位置xy中确定它的能量时,这个算法需要总运行时间O(|v|2)。
对于现实世界中的问题O(|v|2)算法是非常耗时的。
我们已经开发了一种基于网格的计算Dxy的方法,它允许每个顶点在恒定时间,O(1),内确Dxy的近似值,从而将总运行时间减少到令人满意的O(V)。
Fruchterman8所讨论的网格变量算法使用一种binning技术来考虑特定区域内的那些顶点。
一种方法是,通过对顶点的均匀分布把计算减少到O(V)。
然而,如果边的数量很小,那么图形就只有一个均匀的分布。
高度连接的图形在小区域中会有密集的顶点集中,并且运行时间不再是线性的,而是取决于顶点数量。
为了对所有的图形有效,我们的排斥项利用了非特定密度度量。
顶点不会被其他特定的顶点排斥,而是被普遍的过度拥挤所排斥。
这种对排斥力标准的微小修改使得计算复杂度大大降低。
这种密度场density field算法是通过让每个节点将能量足迹footprint放置在二维(密度场)阵列上实现的。
能量足迹可以是空间中的任何函数。
我们的实现:使用一个半径为r的圆和一个在圆的中心能量达到峰值的函数,同时从圆的中心向外的距离能量下降。
总密度场是该区域每个顶点的贡献之和。
考虑到密度字段,每个节点可以使用一个常数时间表来查找并确定近似的Dxy值。
这种方法将斥力项的计算复杂度从O(|V|2)降低到O(|V|),并且与我们的第四个原则相一致,这是使文中算法可以应用到实际场景的重要内容。
计算实验
为了测试算法的稳定性,我们用不同的种子进行了100次重新排列。
在一个布局中(序列),视觉地标记了每个聚类的元素,并观察它们是否在另一个布局中视觉上仍然聚集在一起。
然后我们计算了如下所述的社区统计数据。
为了确定微小的变化或噪音是否会对分类结果产生改变,我们执行了八十组添加了符合一定规则的噪声的re-ordinations,规则是噪音符合高斯分布、均值为零、标准偏差分别为0.001,0.010,0.050,和0.100,这些噪音的相关性被切断以保持相关系数的有效范围是(-1.0 + 1.0)。
这些不同的序列的最后布局均在视觉和统计上进行了比较。
评估方法
我们用一种邻域分析法neighborhoods analysis来比较不同的序列ordinations。
当两个序列非常相似时,我们有理由相信,对于每一个基因,它的最接近的邻居,比如临近的60个基因在这两个序列中几乎是相同的。
事实上,我们对全部序列都有上述的期待。
另一方面,如果这些序列几乎没有什么共同之处,那么观察一个在两序列中都有相同的邻居的基因是很罕见的。
我们计算了这两种序列中每个基因的邻居统计数据。
对于两个序列中的每一个基因,我们分别确定60个最近的基因,然后计算出共同的基因数量。
这个数字被用来增加表中的值,所以最后,我们有一个柱状图展示了在这两个序列中的没有共同邻居的基因数量,有多少有一个共同邻居的基因数量,等等,一直到在两个序列中都有相同的60个邻居的基因数量。由上述可以表示为直方图,如图8所示。
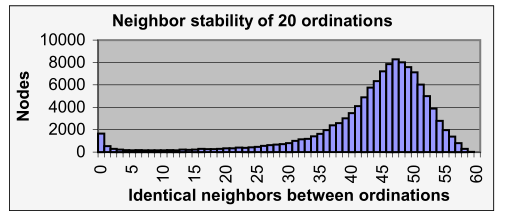
图8.随机起始条件下序列的邻居分布,20副本
We then visually compared the results of the two ordinations by coloring all of the genes in a cluster found in the first ordination and seeing where those colored genes were placed in the other ordination (so that a similar ordination would not break up the group of colored genes, but would still have them co-located;
然后我们对 在第一个序列中发现的某个聚类中所有的基因进行着色并观察这些彩色基因被放置在另一个序列中的布局结果,然后将这两个序列的结果进行比较(所以类似的序列不会破坏有色基因的位置,参见图9和图10)。

图9.有不同的随机初始条件的序列的布局结果
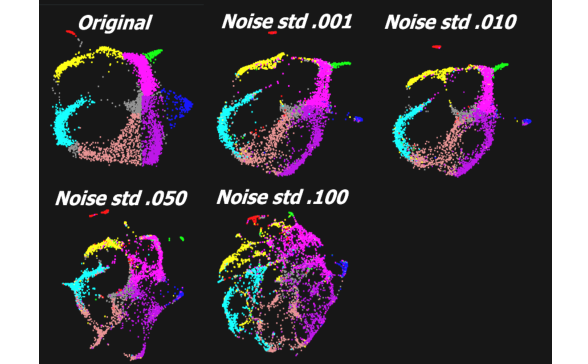
图10.演示了增加边噪声对聚类的稳定性
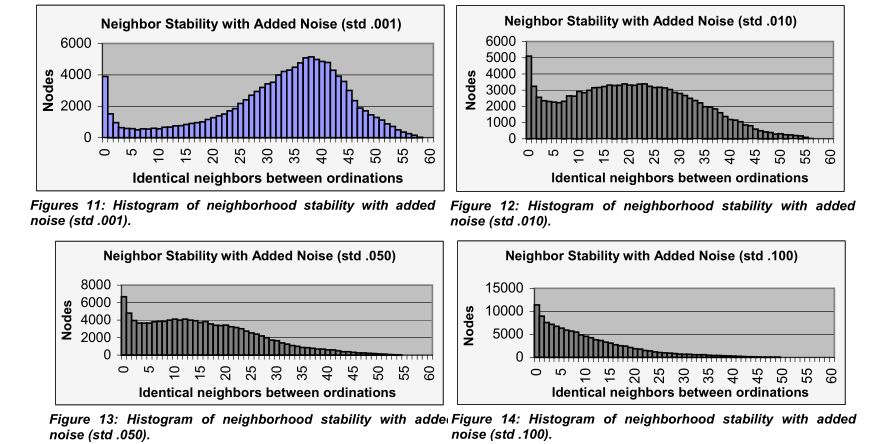
图11.添加了噪音(std.001)的邻域稳定性的直方图
图12.添加了噪音(std.010)的邻域稳定性的直方图
图13.添加了噪音(std.050)的邻域稳定性的直方图
图14.添加了噪音(std.100)的邻域稳定性的直方图
结果和讨论
计算实验揭示了两种类型的信息。
首先,我们发现大型结构通常非常健壮,可以从不同的初始条件开始。
其次,在有差异的地方,关于为什么聚类位置改变的见解和它们确实改变的事实一样有趣。
我们提出了两种衡量这些结构稳定性的方法:视觉解释,以及我们邻域分析的结果。
视觉解释在清晰度上是惊人的,但同时也得到了柱状图所示的数值结果的支持。
直方图的数字可以被解释为从二项分布中提取的数据。
例如,如果这两个序列是完全随机的,那么第二个序列中的一个基因的邻居就会从所有其他基因中随机抽取。
考虑到我们有6000个基因,并且使用了60个左右的邻域,大约是整个基因的1%,在交叉点intersection恰好有k个邻居的概率是
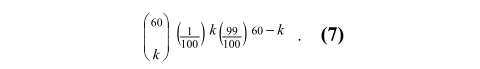
当邻域的大小是基因总数的1%时观察0个邻居的预期频率大约是0.547;
观察一个邻居的期望频率是0.332;
两个邻居的频率大约是0.099,这使得观察三个或更多的邻居的期望频率只有0.022。
对于6000个基因来说,随机状态下,只有132个基因在两个随机序列之间有两个以上的共同之处,而实际上有几千个基因被观察到。
因此,柱状图和视觉比较表明,我们的排列组合之间的差异与随机的差别非常大。
图9显示了来自不同初始条件的6个典型的序列。
第一个序列的布局是用手和颜色勾勒出来的。
在其他的序列布局中,这些相同的基因被跟踪观察它们的相对位置是如何变化的。
两个引人注目的模式出现了。
在一个案例中,尽管有不同的随机种子,但聚类与第一个的聚类几乎完全相同。
在第二种情况下,产生的聚类是初始聚类的镜像。
这种镜像是非常合理的,因为只要保持相对距离,就没有理由期望任何首选的自然位置,所以旋转和镜像应该是很正常且可以被观察到的。
柱状图显示了镜像布局的良好的邻域特性(符合先前的预期)。
对结构的更密切关注确实揭示了一些大的变化,例如在图9中,我们注意到红色聚类从内部翻转到外部的位置。
这个红色的聚类有一些非常相似的连接,将它与山脊连接起来,如图3所示。
因此,它可以很容易地出现在山脊的相反方向/镜像位置。
请注意,邻域分析只会在两个的边界frontiers上发现一些差异。
正如预期的那样,柱状图显示的两个序列在邻里分析上几乎没有差别。
最令人鼓舞的事实是,大多数群体不仅在不同的初始条件下维持他们的相对位置,而且他们还保持着相似的聚类形状,这表示良好的内部一致性,这又一次得到了直方图的支持。
这些结果表明,当呈现同一数据集时,序化工具具有健壮的稳定性。
有了这些信息,我们就开始了对相似数据的微小变化如何影响聚类位置的研究。
理想情况下,人们会想要一种序化算法,它能对相似点的细微变化做出反应,即在布局中产生微小的变化。在某种程度上,其会影响布局从有序的状态到完全无序的、高熵的状态,因为相似点与越来越多的噪音混合在一起。
图10显示了基于实际相似性的初始聚类,以及在相关性中添加了越来越多的噪声的4个情况。
图11-14是相应的直方图,反映了与不断增加的噪声相关的变化。
值得注意的是,随着噪音的增加,一些大的结构仍然完好无损,但是有些,例如紫色和棕色的簇会变得更加无序。
它们本质上随着噪音的增加而融化。
另外,注意红色和绿色的点簇显然更能抵抗噪音。
这个熔化的比喻特别合适,因为它反映了在聚类群开始分裂之前必须进行内部顺序的随机化。
将越来越多的噪声与相似点similarities混合在一起,可以快速地看到哪些聚簇更有可能是工件artifact;
这些是在最小的噪音中融化的聚类。
这些信息很容易获得,我们相信它应该是基于聚类的每个分析的一部分。
结论
理解和使用稳定性是这里提出的重要主题。
尤其重要的是:
- 确保聚类工具对随机起始条件的稳定性
- 确保可能的聚类的范围是充分覆盖(通过系统地搜索一个大范围的选择,或使用一个工具,不需要先验判断聚类的数量)
- 使用聚类工具应对逐渐添加噪声的反映来深入了解聚簇的实际强度。
The two important analysis strategies presented here are: (1) use a probability weighted transformation of the correlation coefficients for the similarities, and (2) compute a small series of clusters with similarities mixed with increasing noise.
这里提出的两个重要的分析策略是:
- 使用相似度的概率加权变换
- 计算一个具有相似性和不断增加的噪声的小系列的聚类。
第一种策略可以更好地分离集群,而第二种策略则能观察单个聚类的强度。
我们还展示了一种有用的视觉方法,通过在一个碱基序列中对基因进行着色,并遵循这些彩色基因在其他序列中的相对运动,来跟踪另一个聚类的效果。
最后,我们提出了一个基于不同聚类下基因的本地邻居的交集的统计指标。
致谢
我们要感谢查克迈耶斯的开始和资助在这个富有成果的领域的工作;
玛格丽特沃纳-沃什伯恩和斯图亚特金帮助使这成为微阵列分析的有用工具;
其余的开发团队包括布鲁斯亨德里克森、大卫约翰逊和海伦科勒。
我们也要感谢审查人员的有益评论和更正。
References
[ 1 ] Davidson, G.S., Hendrickson, B., Johnson, D.K., Meyers, C.E. & Wylie, B.N. Knowledge mining with VxInsight: discovery through interaction . Journal of Intelligent Information Systems 11, 1998, 259-285.
[ 2 ] Spellman, P.T., Sherlock, G., Zhang, M.Q., Iyer, V.R., Anders, K., Eisen, M.B., Brown, P.O., Botstein, D. and Futcher, B., Comprehensive identification of cell cycle-regulated genes of the yeast Saccharomyces cerevisiae by microarray hybridization , Mol. Biology of the Cell, 1998, 9:3273-3297.
[ 3 ] Wise, J.A., Thomas, J.J., Pennock, K., Lantrip, D., Pottier, M., Schur, A., & Crow, V. Visualizing the Non-Visual: Spatial Analysis and Interaction with Information from Text Documents , Proceedings of InfoVis ‘95, IEEE, 1995, 51-58.
[ 4 ] Kohonen, T. Self-organized formation of topologically correct feature maps . Biological Cybernetics, 1982, 43:59-69.
[ 5 ] MacQueen, J. Some methods for classification and analysis of multivariate observations . Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability. Volume I: Statistics,. University of California Press, Berkeley and Los Angeles, CA, 1967, pages 281-297
[ 6 ] York, J., Bohn, S., Pennock, K., & Lantrip, D. Clustering and Dimensionality Reduction in SPIRE . Symp. on Advanced Intelligence Processing and Analysis, (1995), 73
[ 7 ] Wise, J.A. The ecological approach to text visualization . Journal of the American Society for Information Science 50(13), (1999), 1224-1233.
[ 8 ] Wilcox, R.R., Introduction to Robust Estimation and Hypothesis Testing , Academic Press, 1997, ISBN 0-12-751545-3
[ 9 ] Ostel, B., Statistics In Research Basic Concepts and Techniques for Research Workers , Iowa State University Press, Ames, Iowa, USA, 1963
[ 10 ] Fisher, R.A., On the probable error of a coefficient of correlation deduced from a small sample . Metron., 1921, 1 (No.4):3.
[ 11 ] Eades, P., A heuristic for graph drawing , Congressus Numerantium, 42, 1984, 149-160
[ 12 ] Fruchtermann, T. and Rheingold, E. Graph drawing by force-directed placement . Technical Report UIUCDCS-R-90- 1609, Computer Science, Univ. Illinois, Urbana-Champagne, Il., 1990
[ 13 ] Quinn, N. and Breur M., A force directed component placement procedure for printed circuit boards , IEEE Trans on Circuits and Systems, 1979, CAS-26, (6), 377-388
[ 14 ] Otten, R. and van Ginneken, L., The Annealing Algorithm , Kluwer Academic Publishers, Boston MA., 1989
[ 15 ] Kamada, T. and Kawai, S., Automatic display of network structures for human understanding , Technical Report 88-007, Department of Information Science, Tokyo University, 1988
[ 16 ] Davidson, R. and Harel, D., Drawing graphs nicely using simulated annealing , Technical Report CS89-13, Department of Applied Mathematics and Computer Science, The Weizmann Institute, Rehovot, Israel., 1989
[ 17 ] Kamada, T. and Kawai, S., An algorithm for drawing general undirected graphs , Information Processing Letters, 1989, 31, (1), 7-15
[ 18 ] Kamada, T. and Kawai, S., A simple method for computing general position is displaying three-dimensional objects , Computer Vision, Graphics, and Image Processing, 1988, 41, 43-56
[ 19 ] Kirkpatrick, S. Gelatt, C.D. and Vecchi, M.P., Optimization by simulated annealing , Science, 1983, 220, (4598), 671-680
😒 留下您对该文章的评价 😄
