

从七月末开始,我的NAS就突然不能正常开机了,今天尝试排查了一下错误,结果能够正常启动且正常运行,但正常运行两个小时之后,群晖就又宕机无法开机了,如此反复气死我了,最后简单搞了一下暂时可用了,但依旧没有找到病根。
检查硬件
- 拆卸下来 - 有内存无硬盘状态开机 - 检查是否系统有问题
- 拆卸内存 - 擦拭插槽和插片,插回去后开机 - 检查内存是否有问题
- 装回硬盘 - 开机,看是否正常登入 - 检查硬盘是否有问题
以上是通用的步骤,对于具体的出错位置和原因,可以在我们重新登录群晖之后,通过查看日志中心来发现!
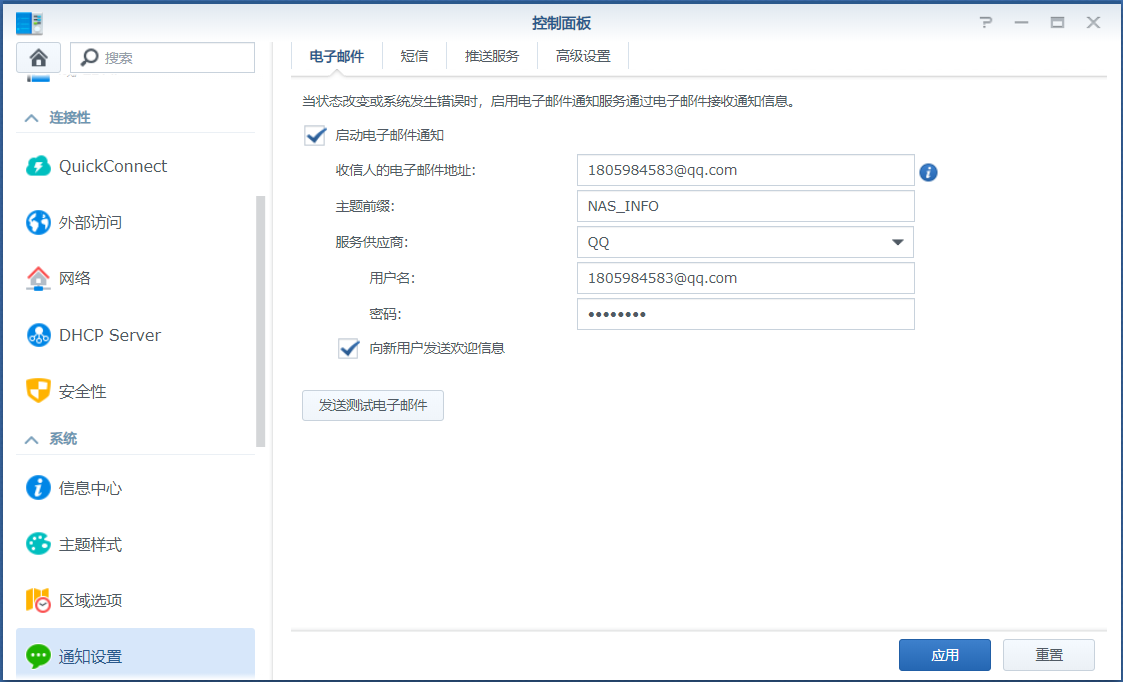
我的故障机器通过拔插硬盘和内存,获得了短暂的复活时间,其实当时我以为是修复了,就在我截图准备写此文时,它居然又挂了,虽然这次我知道是什么问题了,但还是很懵,基本上在靠 UptimeRobot 的监控邮件在确认群晖的死亡,为了更加及时、清晰的知道群晖的宕机时间和原因,我推荐大家把群晖异常的邮件推送给配置上。
配置邮件通知非常简单,在控制面板的通知设置里,把信息填上即可,做完后记得发测试邮件试一试。注意:这里的密码不是QQ账号密码,而是要去QQ邮箱的设置中获取的 16位授权码!
<< 更多精彩尽在『程序萌部落』>>
<< https://www.cxmoe.com >>
定位日志
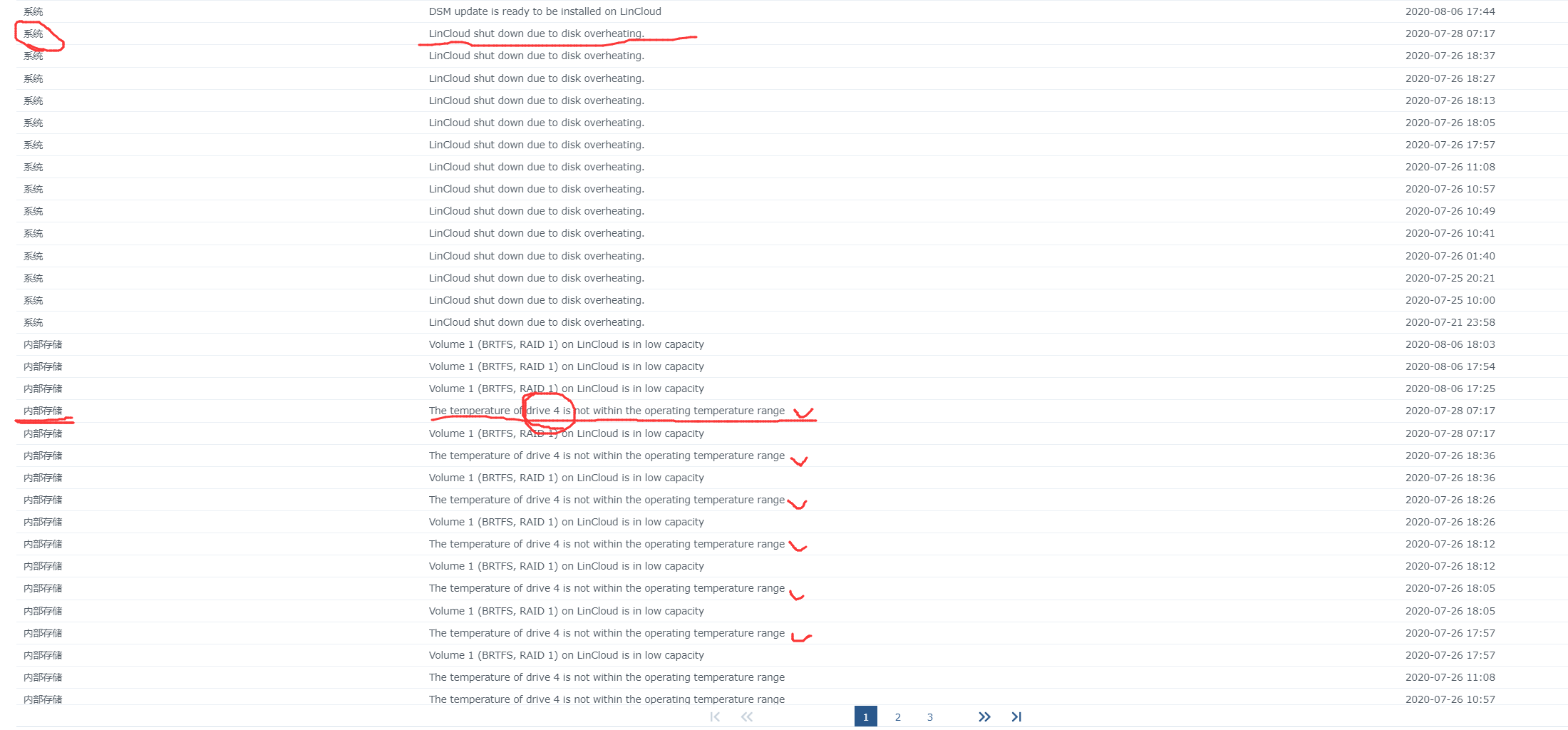
在通过硬件插拔后,我顺利进入了系统,然后通过查看日志这个APP,可以发现很明显的、触发关机的异常,这里是硬盘温度超过保护温度而触发关机保护。
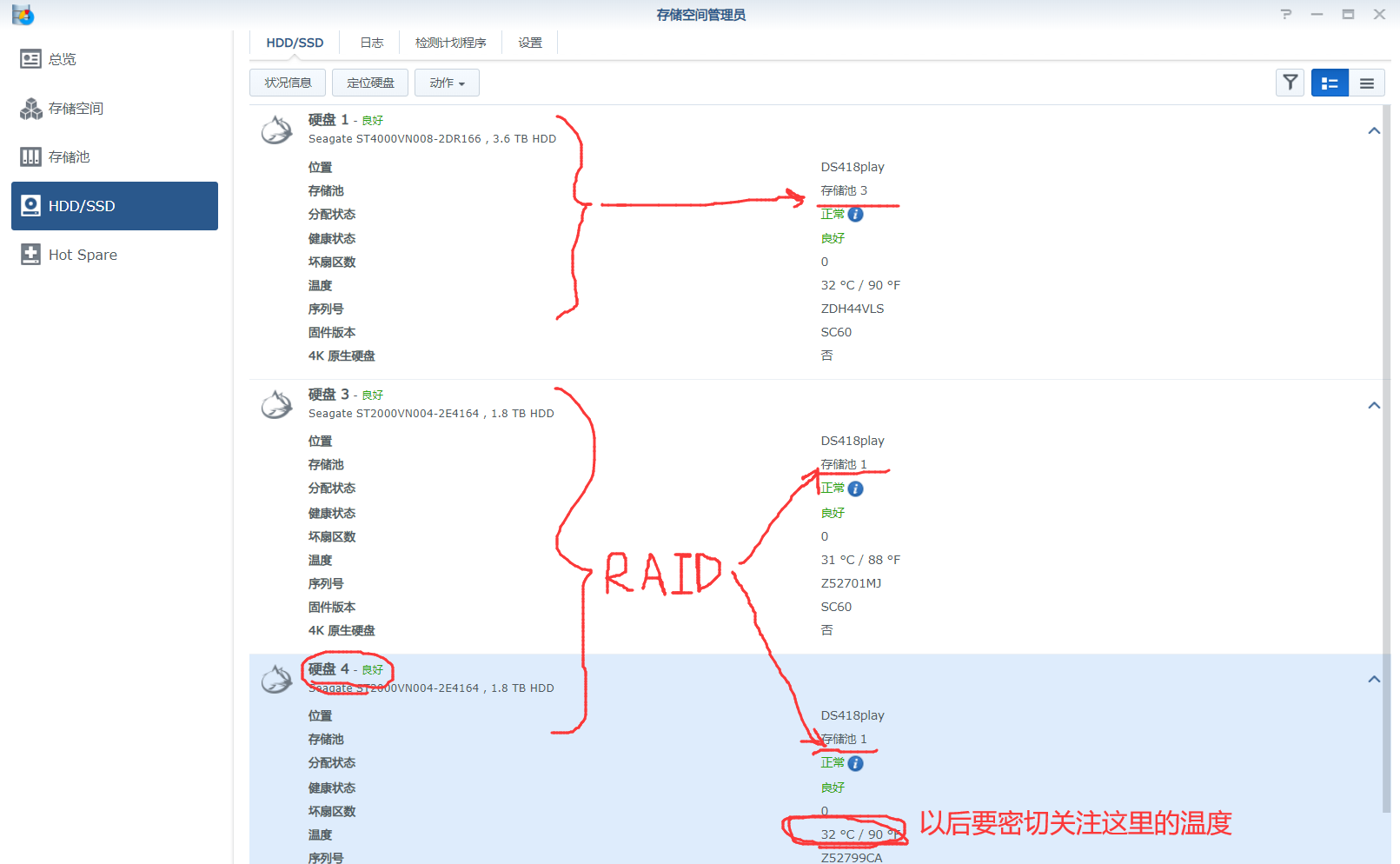
可以看到日志说是drive4的问题,在磁盘管理这个APP中,我们可以找到那块磁盘,不幸的是这块磁盘是我RAID阵列中的一块,可以看到截图时的温度还是很正常的,就在截图后的半小时内,它就又宕机了,如果还是硬盘温度超限,那我就很不解了,因为在此期间我并没有访问什么服务,也就开启了Web端的DSM桌面。
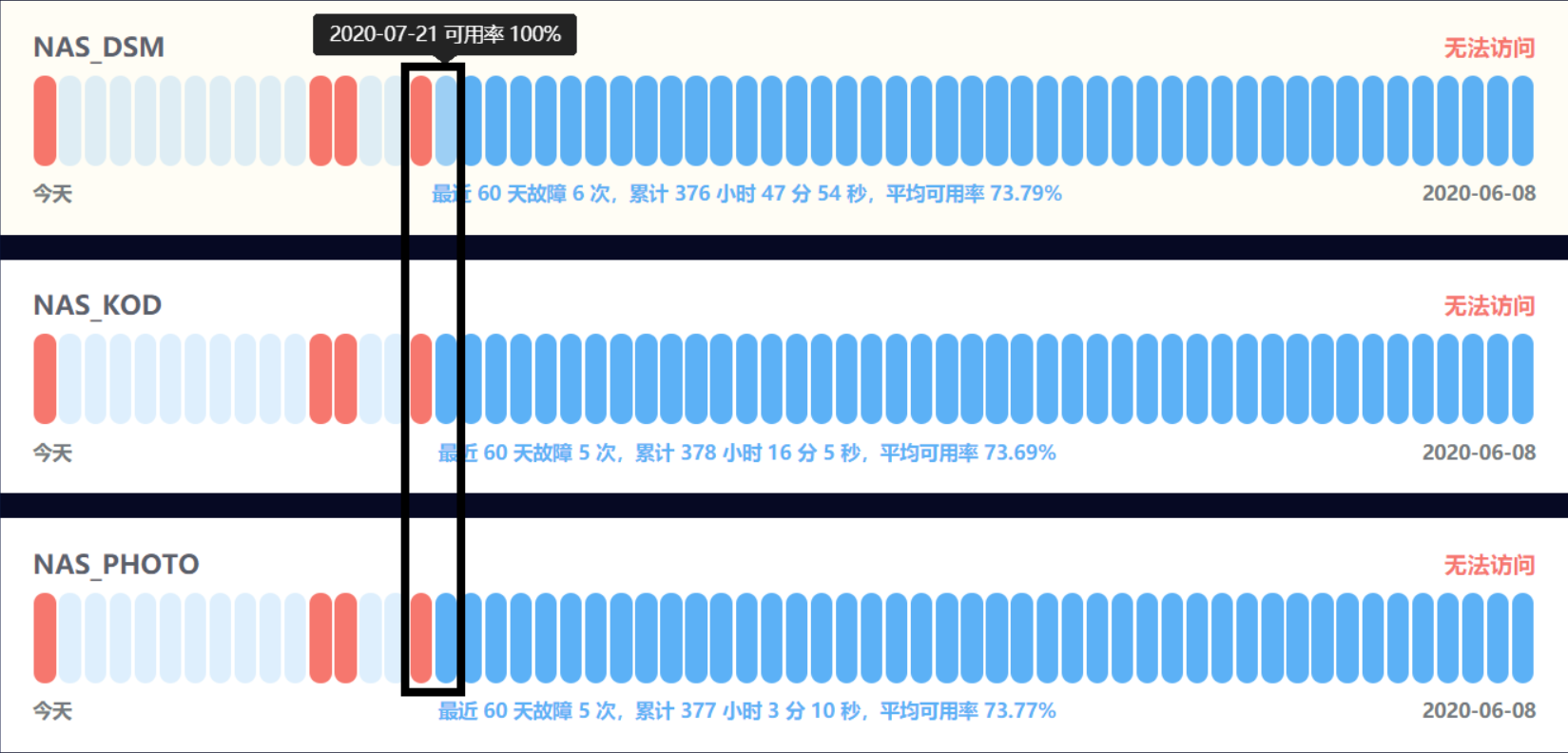
再仔细看日志的日期,或者直接看状态监控,可以发现最早的异常出现在7月22号(准确的说是7.21的23:58),要知道之前的时间跨度内我的群晖是百分百可用的,如果是硬盘老化,照理不会“坏”的这么突然。
可能的推测
在上个月的那段时间我并不记得自己有任何对其的异常操作,所有操作均在七月22号之前很久就做了,我推测这次的硬盘升温并不是由于我的误操作引起的,可能还需要进一步找错误,硬盘4和另一块2T盘是同一时间同时从厂家买的,批号都很相似,讲道理不会有一块突然坏掉吧。。
如果真的是天气热导致的散热问题而引发的,那估计问题不大,天气不热了就没事了,不过还需要进一步观察。
😒 留下您对该文章的评价 😄
