

计算机辅助设计与图形学学报 2016-11
浙江工业大学&浙江大学概述
针对普通客户端浏览和分析大数据困难的问题, 结合 Spark 和 LOD 技术, 以热图为例提出一种面向大数据可视化技术框架. 首先利用 Spark 平台分层并以瓦片为单位并行计算, 然后将结果分布式存储在 HDFS 上, 最后通过web 服务器应用Ajax技术结合地理信息提供各种时空分析服务.文中重点解决了数据点位置和地图之间的映射, 以及由于并行计算导致的热图瓦片之间边缘偏差这2个问题.实验结果表明,该方法将数据交互操作与数据绘制和计算任务分离, 为浏览器端大数据可视化提供了一个新的思路.
目前大数据可视化面临的主要问题包括:
1) 数据复杂散乱. 经常发生数据缺失、数据值不对、结构化程度不高.
2) 迭代式分析成本高. 在初次查询后如果发现结果不对, 改变查询条件重新查询代价高.
3) 构建复杂工作流困难. 从多数据源取得包含各种不同特征的原始数据,然后执行机器学习算法或者复杂查询, 探索过程漫长.
4) 受到原有技术限制, 对小规模数据分析很难直接扩展到大数据分析.
5) 数据点的规模超过普通显示器可能提供的有效像素点.
Hadoop和Spark先后成为大数据分析工业界的研究热点,前者是一个能够对大量数据提供分布式处理的软件框架和文件系统(hadoopdistrib-utedfilesystem,HDFS);后者是一个通用大数据计算平台,可以解决大数据计算中的批处理、 交互查询及流式计算等核心问题.Zeppelin可以作为Spark的解释器,进一步提供基于 Web 页面的数据分析和可视化协作可以输出表格、柱状图、折线图、饼状图、点图等,但是无法提供更为复杂的交互分析手段.
相关工作
面向 web 的轻量级数据可视化工具主要是一些JavaScript库,利用canvas或者svg画散点,svg不能支持十亿以上的节点,使用 canvas 画布绘图的heatmap.js 在面对大数据量时也无能为力.
热图是一种常用的基本数据可视化技术,通常用颜色编码数值大小,并以矩阵或方格形式整齐排列,在二维平面或者地图上呈现数据空间分布,被广泛应用在许多领域.近年来,许多研究者成功地将热图应用在眼动数据可视分析上, 有效地概括并表达用户视觉注意力的累计分布
LOD针对数据可视化绘制速度慢、效率低等问题,孙敏等提出基于格网划分的LOD(levelsofdetail)分层方法, 实现对大数据集 DEM 数据的实时漫游.
并行计算大数据热图
- 经纬度换算
- 并行计算
在 Spark 平台上实现热图的绘制,首先将经纬度坐标转换为对应不同瓦片上的像素坐标.每个基站的辐射范围可近似认为相同, 即每个基站(收集数据的基站坐标)的初始影响力近似相同,因此可采用影响力叠加法将数据点绘制到画布上,然后做径向渐变,叠加出每个位置的影响大小,得到初始灰度图,如图2a所示.然后将每一个像素点着色,根据每个像素的灰度值大小,以及调色板将灰度值映射成相对应的颜色. 图 2b 是一个透明的PNG 格式图片, 调色板如图 2c 所示. 本文中出现的热图均采用图 2c 调色板.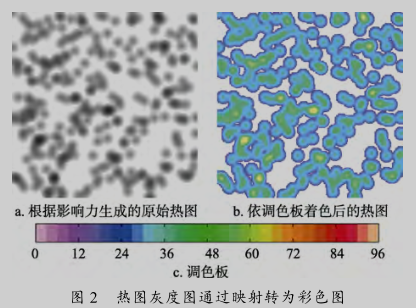
将计算出的热图结果存储在HDFS上,并与经纬度以及层级建立索引关系方便以后读取,拼接后的热图绘制效果如图 3 所示.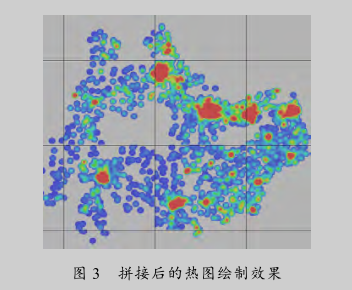
<< 更多精彩尽在『程序萌部落』>>
<< https://www.cxmoe.com >>
瓦片边缘问题
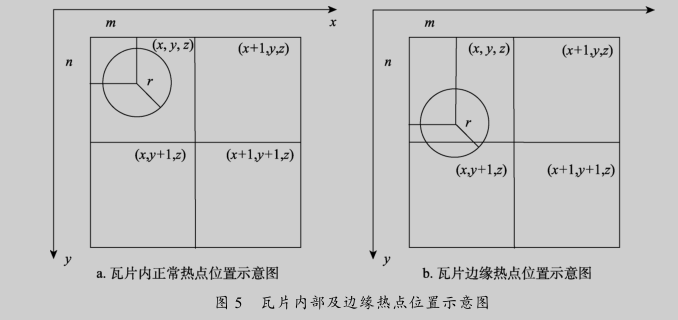
边缘热点可能处于2片或者4片瓦片之间,因此需要通过2次或者4次重复计算.通过本文提出的重叠计算方法可以解决热图分片计算的边缘问题。
实验

总结
本文提出的大数据热图可视化方法能够有效地解决前端绘制计算量大的问题,通过在Spark平台上以瓦片为单位分层次并行计算热图, 将生成的热图存储在HDFS上,然后通过web服务器提供浏览器交互服务, 用户可以通过在地图上拖动鼠标或放大/缩小等操作选择感兴趣区域,再分析不同时间点用户行为差异或渐变过程. 通过解决热图数据点和地图映射关系问题以及瓦片热图之间的边缘问题,提供大数据热图绘方法, 以满足用户交互、协同和共享等多方面需求.该方法可以拓展到其他常用可视化方法,如ScatterPlot, Bar Chart,平行坐标等.但绘制过程是基于Spark计算后得到的离线数据,在实时性上还不能得到保证, 在下一步工作中, 我们将着手利用 Spark Streaming 库来解决这一问题.
😒 留下您对该文章的评价 😄
