

在使用Spark的过程中,一般都会经历调试,提交任务等等环节,如果每个环节都可以确认程序的输入结果,那么无疑对加快代码的调试起了很大的作用,现在,借助IDEA可以非常快捷方便的对Spark代码进行调试,在借助IDEA来完成Spark时,可以大致通过以下几个步骤来完成:
- 初始构建项目阶段,使用Local模式本地运行
- 项目大致完成阶段,使用IDEA连接集群自动提交任务运行
- 最终部署运行阶段,手动将源码包上传到集群并使用 spark-submit 提交任务运行
下面,针对三种方式分别举例说明每种方式需要注意的地方。
使用IDEA本地运行(Local模式)
本地运行,本地计算,本地输出,与集群无关1 | import org.apache.log4j.{Level, Logger} |

使用IDEA本地连接集群运行
运行在集群,计算在集群,输出可以在本地(从远程取回)注意:
1. 此处打包时需要将环境依赖包含在内
2. 注意勾选 Include in build,然后 Rebuild Module 即可打包
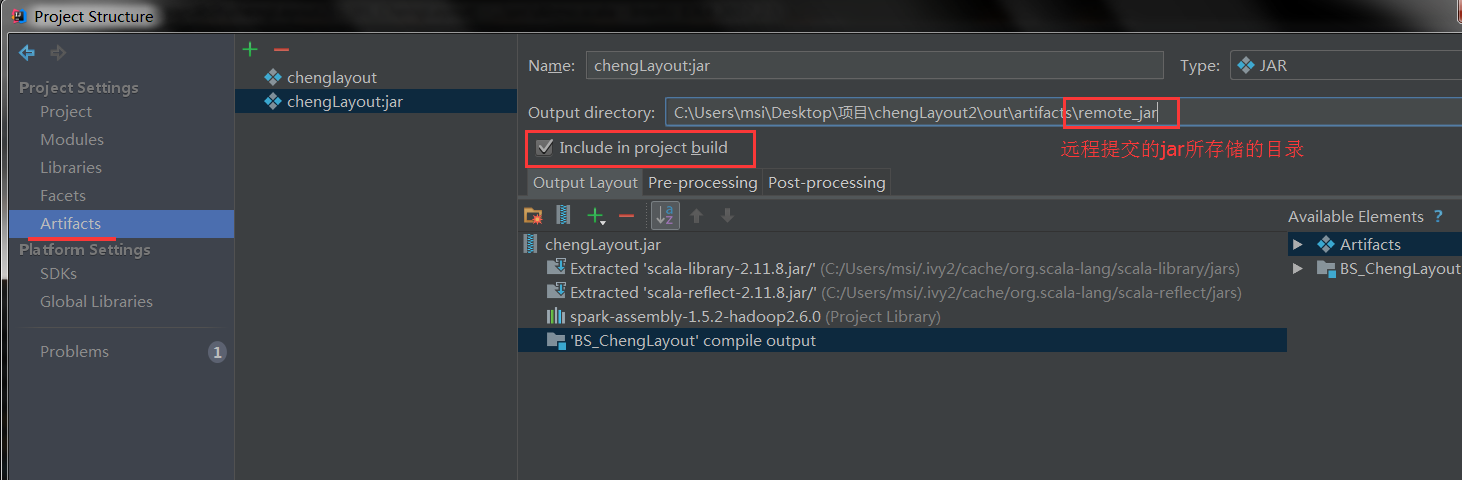
3. 代码内需要指定jar包的具体路径(setJar)和主节点(setMaster)

4. 注意setMaster地址就是webUI中置顶的地址

5. 注意这种方式的代码输出
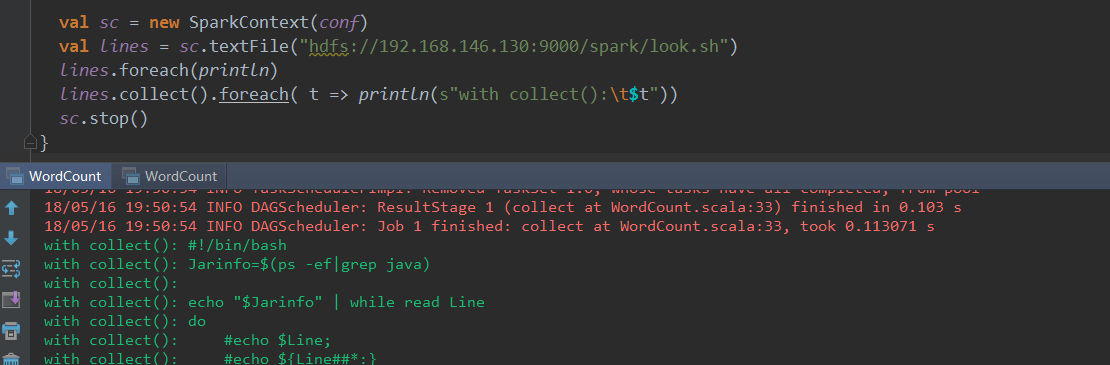
这种方式 rdd.foreach(println) 或者是一般的 println() 都不能在 Console 打印出结果,如果希望在控制台打印出特定输出必须使用 collect() 将数据取回本地(这时可以将本地想象为集群中的一个节点),对于文件也是同理,其操作相当于对远程hdfs的操作,这里不展开.
<< 更多精彩尽在『程序萌部落』>>
<< https://www.cxmoe.com >>
手动上传Jar包到集群运行
运行在集群,计算在集群,输出在集群注意:
1. 此时打包时只打包源码文件,即无需添加环境依赖
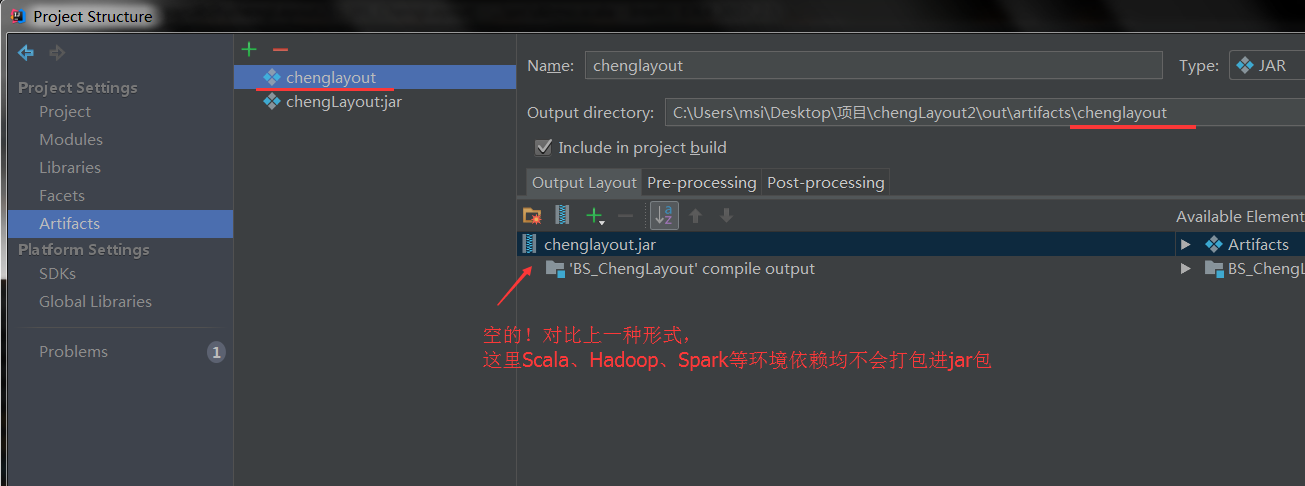
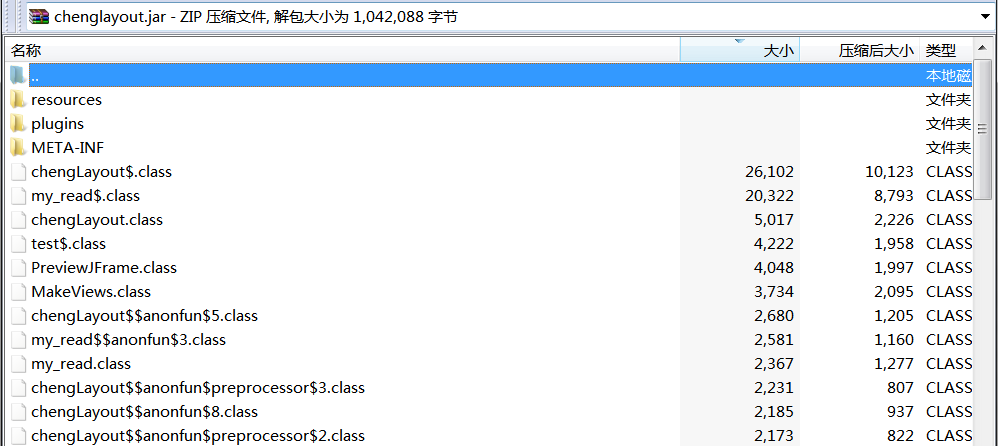
2. 此Jar文件内只有源码,一般很小
3. 代码内 Sparkconf 的获取不用具体指定
1 | import org.apache.log4j.{Level, Logger} |
4. 需要使用 spark-submit 命令提交任务

留意这种形式
1 | import org.apache.spark.{SparkConf, SparkContext} |
上述代码中,Spark仍然是Local模式,但资源文件却在远程集群的HDFS上,这也是可以运行的!这时访问的资源确实是远程的资源,但是计算仍然在本地,仍然算做第一种方式(Local模式)。
结束语
在提交任务的过程中可能会遇到各种各样的问题,一般分为task本身的配置项问题和Spark集群本身的问题两部分,task本身的配置问题一般可以通过:
- SparkContext().set() 来设置,第二种方式即IDEA连接集群
- spark-submit添加参数–executor-memory 来设置,即手动提交方式
- 具体配置项参见[ Spark配置参数 ]
集群本身的问题涉及Worker、Master的启动等等,关联的地方较多,在此不进行展开。
最后,整个提交过程的前提是IDEA项目配置和Spark集群环境的正确,以及两者正确的匹配(比如打包的1.x版本的Saprk任务大概率是不能运行在Spark2.x的集群上的)。
😒 留下您对该文章的评价 😄
