

GraphX 是新的(alpha)的图形和图像并行计算的Spark API。从整理上看,GraphX 通过引入 弹性分布式属性图(Resilient Distributed Property Graph)继承了Spark RDD:一个将有效信息放在顶点和边的有向多重图。为了支持图形计算,GraphX 公开了一组基本的运算(例如,subgraph,joinVertices和mapReduceTriplets),以及在一个优化后的
PregelAPI的变形。此外,GraphX 包括越来越多的图算法和 builder 构造器,以简化图形分析任务。
GraphX 目前是一个 alpha 组件。虽然我们会尽量减少 API 的变化,但是一些 API 可能会在将来的版本中改变。
图并行计算的背景
从社交网络到语言建模,日益扩大的规模和图形数据的重要性已带动许多新的图像并行系统(例如,Giraph和 GraphLab)。通过限制可表示计算的类型以及引入新的技术来划分和分布图,这些系统比一般的数据并行系统在执行复杂图形算法方面有大幅度地提高。
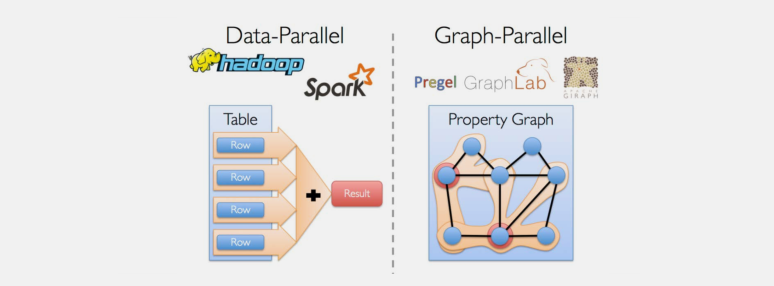
然而,这些限制在获得重大性能提升的同时,也使其难以表达一个典型的图表分析流程中的许多重要阶段:构造图,修改它的结构或表达计算跨越多重图的计算。此外,如何看待数据取决于我们的目标,相同的原始数据,可能有许多不同的表(table)和图表视图(graph views)。

因此,能够在同一组物理数据的表和图表视图之间切换是很有必要的,并利用各视图的属性,以方便地和有效地表达计算。但是,现有的图形分析管道必须由图并行和数据并行系统组成,从而导致大量的数据移动和重复以及复杂的编程模型。
该 GraphX 项目的目标是建立一个系统,建立一个统一的图和数据并行计算的 API。该GraphX API 使用户能够将数据既可以当作一个图,也可以当作集合(即RDDS)而不用进行数据移动或数据复制。通过引入在图并行系统中的最新进展,GraphX能够优化图形操作的执行。
GraphX 替换 Spark Bagel 的 API
在GraphX 的发布之前,Spark的图计算是通过Bagel实现的,后者是Pregel的一个具体实现。GraphX提供了更丰富的图属性API,从而增强了Bagel。从而达到一个更加精简的Pregel抽象,系统优化,性能提升以及减少内存开销。虽然我们计划最终弃用Bagel,我们将继续支持Bagel的API和Bagel编程指南。不过,我们鼓励Bagel用户,探索新的GraphXAPI,并就从Bagel升级中遇到的障碍反馈给我们。
从 Spark 0.9.1 迁移
GraphX 在Spark 1.1.0 包含Spark-0.9.1一个用户面向接口的改变。EdgeRDD现在可以存储相邻顶点属性来构建triplets,因此它获得了一个类型参数。一个Graph[VD,ED]的边的类型是EdgeRDD[ED,VD]而不是 EdgeRDD[ED]。
入门
首先,你要导入 Spark 和 GraphX 到你的项目,如下所示:
1 | import org.apache.spark._ |
如果你不使用Spark shell,你还需要一个 SparkContext。要了解更多有关如何开始使用Spark参考 Spark快速入门指南。
属性图
该 属性图是一个用户定义的顶点和边的有向多重图。有向多重图是一个有向图,它可能有多个平行边共享相同的源和目的顶点。多重图支持并行边的能力简化了有多重关系(例如,同事和朋友)的建模场景。每个顶点是 唯一 的 64位长的标识符(VertexID)作为主键。GraphX并没有对顶点添加任何顺序的约束。同样,每条边具有相应的源和目的顶点的标识符。
该属性表的参数由顶点(VD)和边缘(ED)的类型来决定。这些是分别与每个顶点和边相关联的对象的类型。
GraphX 优化顶点和边的类型的表示方法,当他们是普通的旧的数据类型(例如,整数,双精度等)通过将它们存储在专门的阵列减小了在内存占用量。
在某些情况下,可能希望顶点在同一个图中有不同的属性类型。这可以通过继承来实现。例如,以用户和产品型号为二分图我们可以做到以下几点:
1 | class VertexProperty() |
和 RDDS 一样,属性图是不可变的,分布式的和容错的。对图中的值或结构的改变是通过生成具有所需更改的新图来完成的。注意原始图的该主要部分(即不受影响的结构,属性和索引)被重用,从而减少这个数据结构的成本。该图是通过启发式执行顶点分区,在不同的执行器(executor)中进行顶点的划分。与 RDDS 一样,在发生故障的情况下,图中的每个分区都可以重建。
逻辑上讲,属性图对应于一对类型集合(RDDS),这个组合记录顶点和边的属性。因此,该图表类包含成员访问该图的顶点和边:
1 | class Graph[VD, ED] { |
类 VertexRDD [VD]和 EdgeRDD[ED,VD]继承和并且分别是一个优化的版本的RDD[(VertexID,VD)]和RDD[Edge[ED]]。这两个VertexRDD[VD]和EdgeRDD[ED,VD]提供各地图的计算内置附加功能,并充分利用内部优化。我们在上一节顶点和边RDDS中详细讨论了VertexRDD和EdgeRDD的API,但现在,他们可以简单地看成是RDDS形式的: RDD[(VertexID,VD)]和 RDD [EDGE[ED]] 。
属性图的例子
假设我们要建立一个 GraphX项目各合作者的属性图。顶点属性可能会包含用户名和职业。我们可以使用一组字符注释来描述代表合作者关系的边:
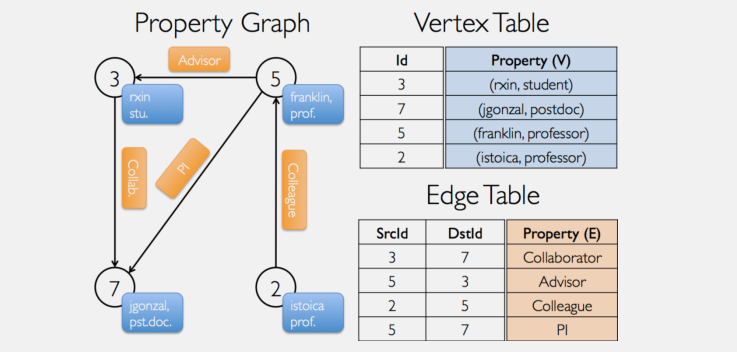
由此产生的图形将有类型签名:
1 | val userGraph: Graph[(String, String), String] |
有许多方法可以从原始数据文件,RDDS,甚至合成生成器来生成图,我们会在 graph builders 更详细的讨论。可能是最通用的方法是使用 Graph ojbect。例如,下面的代码从一系列的RDDS的集合中构建图:
1 | // Assume the SparkContext has already been constructed |
在上面的例子中,我们利用了Edge的case类。Edge具有srcId和dstId,它们分别对应于源和目的地顶点的标识符。此外,Edge 类具有 attr属性,并存储的边的特性。
我们可以通过 graph.vertices 和 graph.edges属性,得到图到各自的顶点和边的视图。
1 | val graph: Graph[(String, String), String] // Constructed from above |
需要注意的是graph.vertices返回VertexRDD[(String,String)]延伸RDD[(VertexID,(String,String))],所以我们使用Scala的case表达来解构元组。在另一方面,graph.edges返回EdgeRDD包含Edge[String]对象。我们可以也使用的如下的类型的构造器:
1 | graph.edges.filter { case Edge(src, dst, prop) => src > dst }.count |
除了 图的顶点和边的意见,GraphX 也提供了三重视图。三重视图逻辑连接点和边的属性产生的 RDD[EdgeTriplet [VD,ED]包含的实例 EdgeTriplet类。此 连接 可以表示如下的SQL表达式:
1 | SELECT src.id, dst.id, src.attr, e.attr, dst.attr |
或图形方式:

该 EdgeTriplet类继承了 Edge并加入了类属性:srcAttr和dstAttr,用于包含了源和目标属性。我们可以用一个图的三元组视图渲染描述用户之间的关系字符串的集合。
1 | val graph: Graph[(String, String), String] // Constructed from above |
Graph 操作
正如RDDs有这样基本的操作mpa,filter,和reduceByKey,属性图也有一系列基本的运算,采用用户定义的函数,并产生新的图形与变换的性质和结构。定义核心运算已优化的实现方式中定义的Graph,并且被表示为核心操作的组合定义在GraphOps。然而,由于Scala的implicits特性,GraphOps中的操作会自动作为Graph的成员。例如,我们可以计算各顶点的入度(定义在的 GraphOps):
1 | val graph: Graph[(String, String), String] |
将核心图操作和 GraphOps区分开来的原因是为了将来能够支持不同的图表示。每个图的表示必须实现核心操作并且复用 GraphOps中很多有用的操作。
运算列表总结
以下列出了Graph图 和 GraphOps中同时定义的操作.为了简单起见,我们都定义为Graph的成员函数。请注意,某些函数签名已被简化(例如,默认参数和类型的限制被删除了),还有一些更高级的功能已被删除,完整的列表,请参考API文档。
1 | /** Summary of the functionality in the property graph */ |
属性操作
和RDD的 map操作类似,属性图包含以下内容:
1 | class Graph[VD, ED] { |
每个运算产生一个新的图,这个图的顶点和边属性通过 map方法修改。
请注意,在所有情况下的图的机构不受影响。这是这些运算符的关键所在,它允许新得到图可以复用初始图的结构索引。下面的代码段在逻辑上是等效的,但第一个不保留结构索引,所以不会从 GraphX 系统优化中受益:
1 | val newVertices = graph.vertices.map { case (id, attr) => (id, mapUdf(id, |
相反,使用 mapVertices保存索引:
1 | val newGraph = graph.mapVertices((id, attr) => mapUdf(id, attr)) |
这些操作经常被用来初始化图的特定计算或者去除不必要的属性。例如,给定一个将出度作为顶点的属性图(我们之后将介绍如何构建这样的图),我们初始化它作为 PageRank:
1 | // Given a graph where the vertex property is the out-degree |
结构操作
当前 GraphX 只支持一组简单的常用结构化操作,我们希望将来增加更多的操作。以下是基本的结构运算符的列表。
1 | class Graph[VD, ED] { |
该reverse操作符返回一个新图,新图的边的方向都反转了。这是非常实用的,例如,试图计算逆向PageRank。因为反向操作不修改顶点或边属性或改变的边的数目,它的实现不需要数据移动或复制。
该子图subgraph将顶点和边的预测作为参数,并返回一个图,它只包含满足了顶点条件的顶点图(值为true),以及满足边条件 并连接顶点的边。subgraph子运算符可应用于很多场景,以限制图表的顶点和边是我们感兴趣的,或消除断开的链接。例如,在下面的代码中,我们删除已损坏的链接:
1 | // Create an RDD for the vertices |
注意,在上面的例子中,仅提供了顶点条件。如果不提供顶点或边的条件,在subgraph 操作中默认为 真 。
mask操作返回一个包含输入图中所有的顶点和边的图。这可以用来和subgraph一起使用,以限制基于属性的另一个相关图。例如,我们用去掉顶点的图来运行联通分量,并且限制输出为合法的子图。
1 | // Run Connected Components |
该 groupEdges操作合并在多重图中的平行边(即重复顶点对之间的边)。在许多数值计算的应用中,平行的边缘可以加入 (他们的权重的会被汇总)为单条边从而降低了图形的大小。
Join 操作
在许多情况下,有必要从外部集合(RDDS)中加入图形数据。例如,我们可能有额外的用户属性,想要与现有的图形合并,或者我们可能需要从一个图选取一些顶点属性到另一个图。这些任务都可以使用来 join 经操作完成。下面我们列出的关键联接运算符:
1 | class Graph[VD, ED] { |
该 joinVertices运算符连接与输入RDD的顶点,并返回一个新的图,新图的顶点属性是通过用户自定义的 map功能作用在被连接的顶点上。没有匹配的RDD保留其原始值。
需要注意的是,如果RDD顶点包含多于一个的值,其中只有一个将会被使用。因此,建议在输入的RDD在初始为唯一的时候,使用下面的 pre-index 所得到的值以加快后续join。
1 | val nonUniqueCosts: RDD[(VertexID, Double)] |
更一般 outerJoinVertices操作类似于joinVertices,除了将用户定义的map函数应用到所有的顶点,并且可以改变顶点的属性类型。因为不是所有的顶点可能会在输入匹配值RDD的mpa函数接受一个Optin类型。例如,我们可以通过
用 outDegree 初始化顶点属性来设置一个图的 PageRank。
1 | val outDegrees: VertexRDD[Int] = graph.outDegrees |
您可能已经注意到,在上面的例子中采用了多个参数列表的curried函数模式(例如,f(a)(b))。虽然我们可以有同样写f(a)(b)为f(a,b),这将意味着该类型推断b不依赖于a。其结果是,用户将需要提供类型标注给用户自定义的函数:
1 | val joinedGraph = graph.joinVertices(uniqueCosts, |
邻居聚集
图形计算的一个关键部分是聚集每个顶点的邻域信息。例如,我们可能想要知道每个用户追随者的数量或每个用户的追随者的平均年龄。许多图迭代算法(如PageRank,最短路径,连通分量等)反复聚集邻居节点的属性, (例如,当前的 PageRank 值,到源节点的最短路径,最小可达顶点 ID)。
mapReduceTriplets
GraphX中核心(大量优化)聚集操作是 mapReduceTriplets操作:
1 | class Graph[VD, ED] { |
该 mapReduceTriplets运算符将用户定义的map函数作为输入,并且将map作用到每个triplet,并可以得到triplet上所有的顶点(或者两个,或者空)的信息。为了便于优化预聚合,我们目前仅支持发往triplet的源或目的地的顶点信息。用户定义的reduce功能将合并所有目标顶点相同的信息。该mapReduceTriplets操作返回 VertexRDD [A] ,包含所有以每个顶点作为目标节点集合消息(类型 A)。没有收到消息的顶点不包含在返回 VertexRDD。
需要注意的是 mapReduceTriplets需要一个附加的可选activeSet(上面没有显示,请参见API文档的详细信息),这限制了 VertexRDD地图提供的邻接边的map阶段:
1 | activeSetOpt: Option[(VertexRDD[_], EdgeDirection)] = None |
该EdgeDirection指定了哪些和顶点相邻的边包含在map阶段。如果该方向是in,则用户定义的 mpa函数 将仅仅作用目标顶点在与活跃集中。如果方向是out,则该map函数将仅仅作用在那些源顶点在活跃集中的边。如果方向是 either,则map函数将仅在任一顶点在活动集中的边。如果方向是both,则map函数将仅作用在两个顶点都在活跃集中。活跃集合必须来自图的顶点中。限制计算到相邻顶点的一个子集三胞胎是增量迭代计算中非常必要,而且是GraphX 实现Pregel中的关键。
在下面的例子中我们使用 mapReduceTriplets算子来计算高级用户追随者的平均年龄。
1 | // Import random graph generation library |
注意,当消息(和消息的总和)是固定尺寸的时候(例如,浮点运算和加法而不是列表和连接)时,mapReduceTriplets 操作执行。更精确地说,结果 mapReduceTriplets 最好是每个顶点度的次线性函数。
计算度信息
一个常见的聚合任务是计算每个顶点的度:每个顶点相邻边的数目。在有向图的情况下,往往需要知道入度,出度,以及总度。该GraphOps类包含一系列的运算来计算每个顶点的度的集合。例如,在下面我们计算最大的入度,出度,总度:
1 | // Define a reduce operation to compute the highest degree vertex |
收集邻居
在某些情况下可能更容易通过收集相邻顶点和它们的属性来表达在每个顶点表示的计算。这可以通过使用容易地实现 collectNeighborIds和 collectNeighbors运算。
1 | class GraphOps[VD, ED] { |
需要注意的是,这些运算计算代价非常高,因为他们包含重复信息,并且需要大量的通信。如果可能的话尽量直接使用 mapReduceTriplets。
<< 更多精彩尽在『程序萌部落』>>
<< https://www.cxmoe.com >>
缓存和清空缓存
在Spark中,RDDS默认并不保存在内存中。为了避免重复计算,当他们需要多次使用时,必须明确地使用缓存(见 Spark编程指南)。在GraphX中Graphs行为方式相同。当需要多次使用图形时,一定要首先调用Graph.cache。
在迭代计算,为了最佳性能,也可能需要清空缓存。默认情况下,缓存的RDDS和图表将保留在内存中,直到内存压力迫使他们按照LRU顺序被删除。对于迭代计算,之前的迭代的中间结果将填补缓存。虽然他们最终将被删除,内存中的不必要的数据会使垃圾收集机制变慢。一旦它们不再需要缓存,就立即清空中间结果的缓存,这将会更加有效。这涉及物化(缓存和强迫)图形或RDD每次迭代,清空所有其他数据集,并且只使用物化数据集在未来的迭代中。然而,由于图形是由多个RDDS的组成的,正确地持续化他们将非常困难。对于迭代计算,我们推荐使用 Pregel API,它正确地 unpersists 中间结果。
Pregel 的 API
图本质上是递归的数据结构,因为顶点的性质取决于它们的邻居,这反过来又依赖于邻居的属性。其结果是许多重要的图形算法迭代重新计算每个顶点的属性,直到定点条件满足为止。一系列图像并行方法已经被提出来表达这些迭代算法。GraphX 提供了类似与Pregel 的操作,这是 Pregel 和 GraphLab 方法的融合。
从总体来看,Graphx 中的 Pregel 是一个批量同步并行消息传递抽象 约束到该图的拓扑结构。Pregel 运算符在一系列超步骤中,其中顶点收到从之前的步骤中流入消息的总和,计算出顶点属性的新值,然后在下一步中将消息发送到相邻的顶点。不同于Pregel,而是更像GraphLab消息被并行计算,并且作为edge-triplet,该消息的计算可以访问的源和目的地的顶点属性。没有收到消息的顶点在一个超级步跳过。当没有消息是,Pregel 停止迭代,并返回最终图形。
请注意,不像更标准的 Pregel的实现,在GraphX中顶点只能将消息发送到邻近的顶点,并且信息构建是通过使用用户定义的消息函数并行执行。这些限制使得在 GraphX 有额外的优化。
以下是类型签名 Pregel,以及一个 初始的实现 (注调用graph.cache已被删除)中:
1 | class GraphOps[VD, ED] { |
请注意,Pregel 需要两个参数列表(即graph.pregel(list1)(list2))。第一个参数列表中包含的配置参数包括初始信息,迭代的最大次数,以及发送消息(默认出边)的方向。第二个参数列表包含用于用户定义的接收消息(顶点程序 vprog),计算消息(sendMsg),并结合信息 mergeMsg。
我们可以使用 Pregel 运算符来表达计算,如在下面的例子中的单源最短路径。
1 | import org.apache.spark.graphx._ |
Graph Builder
GraphX 提供多种从RDD或者硬盘中的节点和边中构建图。默认情况下,没有哪种Graph Builder会重新划分图的边;相反,边会留在它们的默认分区(如原来的HDFS块)。Graph.groupEdges需要的图形进行重新分区,因为它假设相同的边将被放在同一个分区同一位置,所以你必须在调用Graph.partitionBy之前调用groupEdges。
1 | object GraphLoader { |
GraphLoader.edgeListFile提供了一种从磁盘上边的列表载入图的方式。它解析了一个以下形式的邻接列表(源顶点ID,目的地顶点ID)对,忽略以#开头的注释行:
1 | # This is a comment |
它从指定的边创建了一个图表,自动边中提到的任何顶点。所有顶点和边的属性默认为1。canonicalOrientation参数允许重新定向边的正方向(srcId < dstId),这是必需的connected-component算法。该minEdgePartitions参数指定边缘分区生成的最小数目;例如,在HDFS文件具有多个块, 那么就有多个边的分割.
1 | object Graph { |
Graph.apply允许从顶点和边的RDDS中创建的图。重复的顶点会任意选择,并在边RDD中存在的顶点, 但不是顶点RDD会被赋值为默认属性。
Graph.fromEdges允许从只有边的元组RDD创建的图,自动生成由边中存在的顶点,并且给这些顶点赋值为缺省值。
Graph.fromEdgeTuples允许从只有边的元组的RDD图中创建图,并将的边的值赋为1,并自动创建边中所存在的顶点,并设置为缺省值。它也支持删除重边; 进行删除重边时,传入 PartitionStrategy的Some 作为uniqueEdges参数(例如,uniqueEdges=Some(PartitionStrategy.RandomVertexCut))。分区策略是必要的,因为定位在同一分区相同的边,才能使他们能够进行重复删除。
顶点和边 RDDs
GraphX 公开了图中 RDD 顶点和边的视图。然而,因为GraphX将顶点和边保存在优化的数据结构,并且为这些数据结构提供额外的功能,顶点和边分别作为VertexRDD和EdgeRDD返回。在本节中,我们回顾一些这些类型的其他有用的功能。
VertexRDDs
该VertexRDD [A]继承RDD [(VertexID, A)],并增加了一些额外的限制 ,每个VertexID只出现 一次 。此外,VertexRDD[A]表示一个顶点集合,其中每个顶点与类型的属性为A。在内部,这是通过将顶点属性中存储在一个可重复使用的哈希表。因此,如果两个VertexRDDs继承自相同的基类VertexRDD(例如,通过filter或mapValues ),他们可以参加在常数时间内实现合并,而不需要重新计算hash值。要充分利用这个索引数据结构,VertexRDD提供了以下附加功能:
1 | class VertexRDD[VD] extends RDD[(VertexID, VD)] { |
请注意,例如,如何filter操作符返回一个VertexRDD。过滤器使用的是实际通过BitSet实现的,从而复用索引和保持能快速与其他 VertexRDD 实现连接功能。 类似地,mapValues 操作不允许mapha函数改变 VertexID,从而可以复用统一HashMap中的数据结构。当两个VertexRDD派生自同一HashMap,并且是通过线性少买而非代价昂贵的逐点查询时,无论是 leftJoin 和 innerJoin 连接时能够识别 VertexRDD 。
该aggregateUsingIndex操作是一种新的有效的从RDD[(VertexID,A)]构建新的VertexRDD的方式。从概念上讲,如果我在一组顶点上构建了一个VertexRDD[B],这是一个在某些顶点RDD[(VertexID,A)]的超集,然后我可以重用该索引既聚集,随后为RDD[(VertexID, A)]建立索引。例如:
1 | val setA: VertexRDD[Int] = VertexRDD(sc.parallelize(0L until 100L).map(id => (id, 1))) |
EdgeRDDs
该EdgeRDD [ED,VD] ,它继承RDD[Edge[ED],以各种分区策略PartitionStrategy将边划分成不同的块。在每个分区中,边属性和邻接结构,分别存储,这使得更改属性值时,能够最大限度的复用。
EdgeRDD 是提供的三个额外的函数:
1 | // Transform the edge attributes while preserving the structure |
在大多数应用中,我们发现,在 EdgeRDD 中的操作是通过图形运算符来实现,或依靠在基类定义的 RDD 类操作。
优化图的表示
关于 GraphX 中如何表示分布式图结构的详细描述,这个话题超出了本指南的范围,一些高层次的理解可能有助于设计可扩展的算法设计以及 API 的最佳利用。GraphX 采用顶点切的方法来分发图划分:
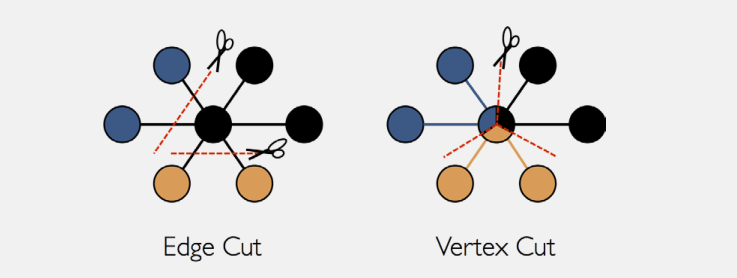
不通过边划分图,GraphX 沿顶点来划分图,这样可以减少顶点之间的通信和存储开销。逻辑上,这对应于将边分配到不同的机器,并允许顶点跨越多个机器。分配边的确切方法取决于PartitionStrategy并有多个权衡各种试探法。用户可以通过重新分区图与不同的策略之间进行选择Graph.partitionBy操作。默认分区策略是按照图的构造,使用图中初始的边。但是,用户可以方便地切换到二维-分区或GraphX中其他启发式分区方法。
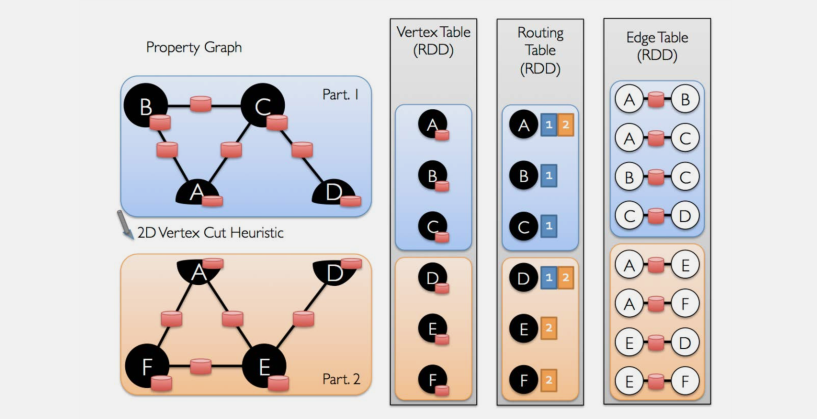
一旦边被划分,并行图计算的关键挑战在于有效的将每个顶点属性和边的属性连接起来。由于在现实世界中,边的数量多于顶点的数量,我们把顶点属性放在边中。因为不是所有的分区将包含所有顶点相邻的边的信息,我们在内部维护一个路由表,这个表确定在哪里广播顶点信息,执行 triplet 和 mapReduceTriplets 的连接操作。
图算法
GraphX 包括一组图形算法来简化分析任务。该算法被包含于org.apache.spark.graphx.lib包中,并可直接通过 GraphOps而被Graph中的方法调用。本节介绍这些算法以及如何使用它们。
PageRank
PageRank记录了图中每个顶点的重要性,假设一条边从u到v,代表从u传递给v的重要性。例如,如果一个Twitter用户有很多粉丝,用户排名将很高。
GraphX 自带的PageRank的静态和动态的实现,放在PageRank对象中。静态的PageRank运行的固定数量的迭代,而动态的PageRank运行,直到排名收敛(即当每个迭代和上一迭代的差值,在某个范围之内时停止迭代)。GraphOps允许Graph中的方法直接调用这些算法。
GraphX 还包括,我们可以将PageRank运行在社交网络数据集中。一组用户给出graphx/data/users.txt,以及一组用户之间的关系,给出了graphx/data/followers.txt。我们可以按照如下方法来计算每个用户的网页级别:
1 | // Load the edges as a graph |
联通分量
连接分量算法标出了图中编号最低的顶点所联通的子集。例如,在社交网络中,连接分量类似集群。GraphX 包含在ConnectedComponents对象的算法,并且我们从该社交网络数据集中计算出连接组件的PageRank部分,如下所示:
1 | // Load the graph as in the PageRank example |
三角计数
当顶点周围与有一个其他两个顶点有连线时,这个顶点是三角形的一部分。GraphX在TriangleCount对象实现了一个三角形计数算法,这个算法计算通过各顶点的三角形数目,从而提供集群的度。我们从PageRank部分计算社交网络数据集的三角形数量。注意TriangleCount要求边是规范的指向(srcId < dstId),并使用 Graph.partitionBy来分割图形。
1 | // Load the edges in canonical order and partition the graph for triangle count |
- 示例
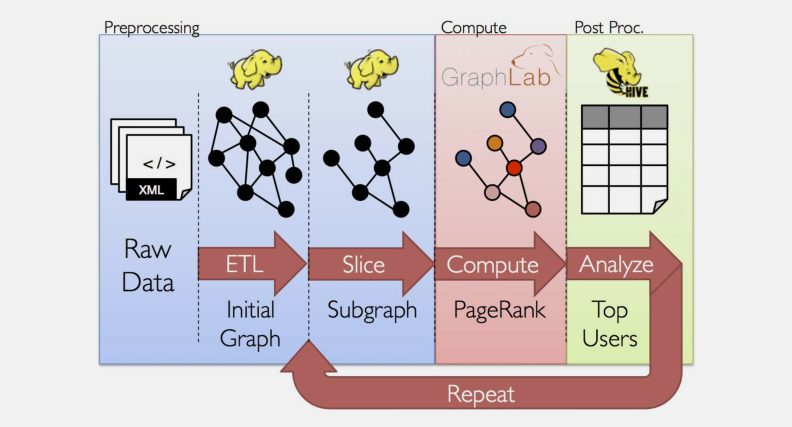
假设我想从一些文本文件中构建图,只考虑图中重要关系和用户,在子图中运行的页面排名算法,然后终于返回与顶级用户相关的属性。我们可以在短短的几行 GraphX 代码中实现这一功能:
1 | // Connect to the Spark cluster |
翻译者:吴卓华
整理自:《Spark GraphX 图计算和图挖掘》
😒 留下您对该文章的评价 😄
